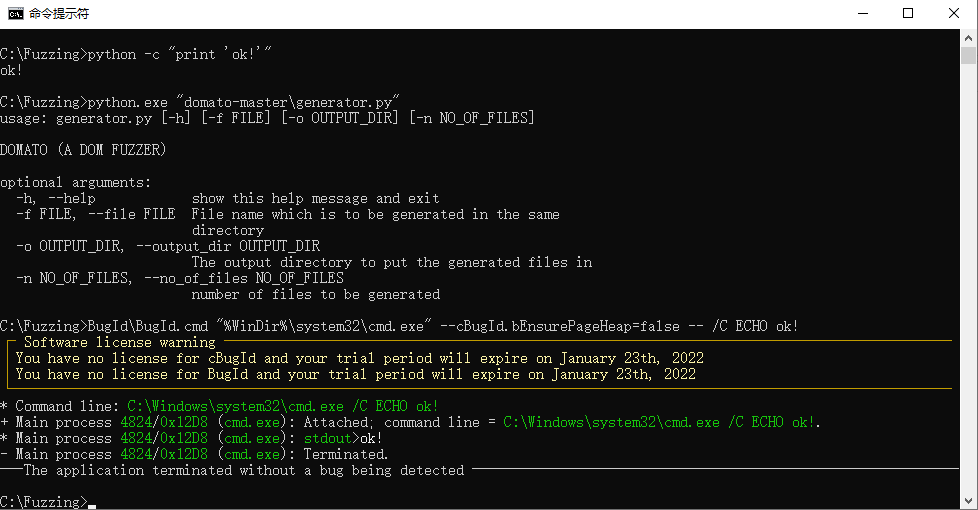
# 开启对应应用程序的页堆:可以使用visual studio附带的gflags,也可以使用bugid带的脚本PageHeap.cmd。四大浏览器开启页堆命令如下。 # 使用PageHeap开启命令需要管理员权限 PageHeap.cmd edge ON PageHeap.cmd chrome ON PageHeap.cmd firefox ON PageHeap.cmd msie ON
@ECHO OFF SET BASE_FOLDER=C:\Fuzzing SET PYTHON_EXE=C:\Python27\python.exe
:: What browser do we want to fuzz? ("chrome" | "edge" | "firefox" | "msie") SET TARGET_BROWSER=msie :: How many HTML files shall we teach during each loop? SET NUMBER_OF_FILES=100 :: How long does it take BugId to start the browser andload an HTML file? SET BROWSER_LOAD_TIMEOUT_IN_SECONDS=30 :: How long does it take the browser to render each HTML file? SET AVERAGE_PAGE_LOAD_TIME_IN_SECONDS=2
:: Optionally configurable SET BUGID_FOLDER=%BASE_FOLDER%\BugId SET DOMATO_FOLDER=%BASE_FOLDER%\domato-master SET TESTS_FOLDER=%BASE_FOLDER%\Tests SET REPORT_FOLDER=%BASE_FOLDER%\Report SET RESULT_FOLDER=%BASE_FOLDER%\Results :: Store our results in a folder named after the target: IFNOT EXIST "%RESULT_FOLDER%\%TARGET_BROWSER%"MKDIR"%RESULT_FOLDER%\%TARGET_BROWSER%"
:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: :: Repeatedly generate tests andrun them in the browser. :LOOP CALL :GENERATE IF ERRORLEVEL 1 EXIT /B 1 CALL :TEST IF ERRORLEVEL 1 EXIT /B 1 GOTO :LOOP
:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: :: Generate test HTML files :GENERATE REM Delete old files. DEL "%TESTS_FOLDER%\fuzz-*.html" /Q >nul 2>nul REM Generate new HTML files. "%PYTHON_EXE%""%DOMATO_FOLDER%\generator.py" --output_dir "%TESTS_FOLDER%" --no_of_files %NUMBER_OF_FILES% IF ERRORLEVEL 1 EXIT /B 1 EXIT /B 0
:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: :: Run browser in BugId andload test HTML files :TEST REM Delete old report if any. IFNOT EXIST "%REPORT_FOLDER%" ( MKDIR"%REPORT_FOLDER%" ) ELSE ( DEL "%REPORT_FOLDER%\*.html" /Q >nul 2>nul ) REM Guess how long the browser needs to run to process all tests. REM This is used by BugId to terminate the browser in case it survives all tests. SET /A MAX_BROWSER_RUN_TIME=%BROWSER_LOAD_TIMEOUT_IN_SECONDS% + %AVERAGE_PAGE_LOAD_TIME_IN_SECONDS% * %NUMBER_OF_FILES% REM Start browser in BugId... "%PYTHON_EXE%""%BUGID_FOLDER%\BugId.py""%TARGET_BROWSER%""--sReportFolderPath=\"%REPORT_FOLDER:\=\\%\"" --nApplicationMaxRunTimeInSeconds=%MAX_BROWSER_RUN_TIME% -- "file://%TESTS_FOLDER%\index.html"
IF ERRORLEVEL 2 ( ECHO - ERROR %ERRORLEVEL%. REM ERRORLEVEL 2+ means something went wrong. ECHO Please fix the issue before continuing... EXIT /B 1 ) ELSEIFNOT ERRORLEVEL 1 ( EXIT /B 0 ) ECHO Crash detected!
REM Create results sub-folder based on report file name and copy test files REM and report. FOR %%I IN ("%REPORT_FOLDER%\*.html") DO ( CALL :COPY_TO_UNIQUE_CRASH_FOLDER "%RESULT_FOLDER%\%%~nxI" EXIT /B 0 ) ECHO BugId reported finding a crash, but not report file could be found!? EXIT /B 1
:COPY_TO_UNIQUE_CRASH_FOLDER SET REPORT_FILE=%~nx1 REM We want to remove the ".html" extension from the report file name to get REM a unique folder name: SET UNIQUE_CRASH_FOLDER=%RESULT_FOLDER%\%TARGET_BROWSER%\%REPORT_FILE:~0,-5% IF EXIST "%UNIQUE_CRASH_FOLDER%" ( ECHO Repro and report already saved after previous test detected the same issue. EXIT /B 0 ) ECHO Copying report and repro to %UNIQUE_CRASH_FOLDER% folder... REM Move report to unique folder MKDIR"%UNIQUE_CRASH_FOLDER%" MOVE "%REPORT_FOLDER%\%REPORT_FILE%""%UNIQUE_CRASH_FOLDER%\report.html" REM Copy repro MKDIR"%UNIQUE_CRASH_FOLDER%\Repro" COPY "%TESTS_FOLDER%\*.html""%UNIQUE_CRASH_FOLDER%\Repro" ECHO Report and repro copied to %UNIQUE_CRASH_FOLDER% folder. EXIT /B 0
<!doctype html> <!-- saved from url=(0014)about:internet --> <html> <head> <script> var oIFrameElement = document.getElementById("IFrame"), nPageLoadTimeoutInSeconds = 5, uIndex = 0; onload = functionfLoadNext() { // Show progress in title bar. var sIndex = "" + uIndex++; while (sIndex.length < 5) sIndex = "0" + sIndex; var sTestURL = "fuzz-" + sIndex + ".html"; document.title = "Loading test " + sTestURL + "..."; // Add iframe element that loads the next test case. var oIFrame = document.body.appendChild(document.createElement("iframe")), bFinished = false; oIFrame.setAttribute("sandbox", "allow-scripts"); oIFrame.setAttribute("src", sTestURL); // Hook load event handler and add timeout to remove the iframe when the test is finished. try { oIFrame.contentWindow.addEventListener("load", fCleanupAndLoadNext); } catch (e) { // This may cause an exception because some browsers treat different files loaded from the // local file system as comming from different origins. }; var xTimeout = setTimeout(fCleanupAndLoadNext, nPageLoadTimeoutInSeconds * 1000); functionfCleanupAndLoadNext() { // Both the load event and the timeout can call this function; make sure we only execute once: if (!bFinished) { bFinished = true; console.log("Finished test " + sTestURL + "..."); // Let's give the page another 5 seconds to render animations etc. setTimeout(function() { // Remove the iframe from the document to delete the test. try { document.body.removeChild(oIFrame); } catch (e) {}; }, 5000); fLoadNext(); }; }; }; </script> </head> <body> </body> </html>
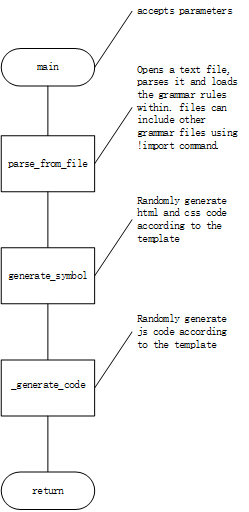
if args.file: generate_samples(template, [args.file]) # 可见generate_samples函数为生成样本的核心函数
elif args.output_dir: ifnot args.no_of_files: print("Please use switch -n to specify the number of files") else: ... outfiles = [] for i inrange(nsamples): outfiles.append(os.path.join(out_dir, 'fuzz-' + str(i).zfill(5) + '.html')) generate_samples(template, outfiles) else: parser.print_help()
# JS and HTML grammar need access to CSS grammar. # Add it as import htmlgrammar.add_import('cssgrammar', cssgrammar) jsgrammar.add_import('cssgrammar', cssgrammar)
for outfile in outfiles: result = generate_new_sample(template, htmlgrammar, cssgrammar, jsgrammar) #writefile
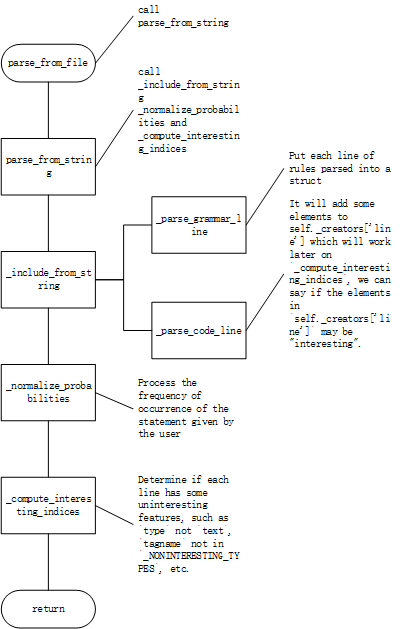
def_parse_grammar_line(self, line): """Parses a grammar rule.""" # Check if the line matches grammar rule pattern (<tagname> = ...). ...
# Parse the line to create a grammar rule. ... # Splits the line into constant parts and tags. For example # "foo<bar>baz" would be split into three parts, "foo", "bar" and "baz" # Every other part is going to be constant and every other part # is going to be a tag, always starting with a constant. Empty # spaces between tags/beginning/end are not a problem because # then empty strings will be returned in corresponding places, # for example "<foo><bar>" gets split into "", "foo", "", "bar", "" ...
# Store the rule in appropriate sets. create_tag_name = rule['creates']['tagname'] if create_tag_name in self._creators: self._creators[create_tag_name].append(rule) else: self._creators[create_tag_name] = [rule] if'nonrecursive'in rule['creates']: if create_tag_name in self._nonrecursive_creators: self._nonrecursive_creators[create_tag_name].append(rule) else: self._nonrecursive_creators[create_tag_name] = [rule] self._all_rules.append(rule) if'root'in rule['creates']: self._root = create_tag_name
def_parse_code_line(self, line, helper_lines=False): """Parses a rule for generating code.""" rule = { 'type': 'code', 'parts': [], 'creates': [] } # Splits the line into constant parts and tags. For example # "foo<bar>baz" would be split into three parts, "foo", "bar" and "baz" # Every other part is going to be constant and every other part # is going to be a tag, always starting with a constant. Empty # spaces between tags/beginning/end are not a problem because # then empty strings will be returned in corresponding places, # for example "<foo><bar>" gets split into "", "foo", "", "bar", "" rule_parts = re.split(r'<([^>)]*)>', line) for i inrange(0, len(rule_parts)): if i % 2 == 0: if rule_parts[i]: rule['parts'].append({ 'type': 'text', 'text': rule_parts[i] }) else: parsedtag = self._parse_tag_and_attributes(rule_parts[i]) rule['parts'].append(parsedtag) if'new'in parsedtag: rule['creates'].append(parsedtag)
for tag in rule['creates']: tag_name = tag['tagname'] if tag_name in _NONINTERESTING_TYPES: continue if tag_name in self._creators: self._creators[tag_name].append(rule) else: self._creators[tag_name] = [rule] if'nonrecursive'in tag: if tag_name in self._nonrecursive_creators: self._nonrecursive_creators[tag_name].append(rule) else: self._nonrecursive_creators[tag_name] = [rule]
def_normalize_probabilities(self): """Preprocessess probabilities for production rules. Creates CDFs (cumulative distribution functions) and normalizes probabilities in the [0,1] range for all creators. This is a preprocessing function that makes subsequent creator selection based on probability easier. """ for symbol, creators in self._creators.items(): cdf = self._get_cdf(symbol, creators) self._creator_cdfs[symbol] = cdf # 维护了一个字典_creator_cdfs,分别表示每个tag对应的概率分布。
def_compute_interesting_indices(self): # select interesting lines for each variable type
if'line'notin self._creators: return
for i inrange(len(self._creators['line'])): self._all_nonhelper_lines.append(i) rule = self._creators['line'][i] for part in rule['parts']: if part['type'] == 'text': # not intersting continue tagname = part['tagname'] if tagname in _NONINTERESTING_TYPES: # not intersting continue if'new'in part: # not intersting continue if tagname notin self._interesting_lines: self._interesting_lines[tagname] = [] self._interesting_lines[tagname].append(i)
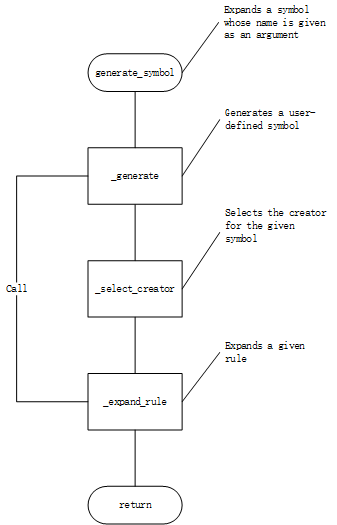
defgenerate_symbol(self, name): """Expands a symbol whose name is given as an argument.""" context = { 'lastvar': 0, 'lines': [], 'variables': {}, 'force_var_reuse': False } return self._generate(name, context, 0)
# Check if we already have a variable of the given type. if (symbol in context['variables'] and symbol notin _NONINTERESTING_TYPES): # print symbol + ':' + str(len(context['variables'][symbol])) + ':' + str(force_var_reuse) if (force_var_reuse or random.random() < self._var_reuse_prob or len(context['variables'][symbol]) > self._max_vars_of_same_type): # print 'reusing existing var of type ' + symbol context['force_var_reuse'] = False variables = context['variables'][symbol] return variables[random.randint(0, len(variables) - 1)] # print 'Not reusing existing var of type ' + symbol
# Add all newly created variables to the context additional_lines = [] for v in new_vars: if v['type'] notin _NONINTERESTING_TYPES: self._add_variable(v['name'], v['type'], context) additional_lines.append("if (!" + v['name'] + ") { " + v['name'] + " = GetVariable(fuzzervars, '" + v['type'] + "'); } else { " + self._get_variable_setters(v['name'], v['type']) + " }")
# Return the result. # In case of 'ordinary' grammar rules, return the filled rule. # In case of code, return just the variable name # and update the context filed_rule = ''.join(ret_parts) if rule['type'] == 'grammar': return filed_rule else: context['lines'].append(filed_rule) context['lines'].extend(additional_lines) if symbol == 'line': return filed_rule else: return ret_vars[random.randint(0, len(ret_vars) - 1)]
for v in initial_variables: self._add_variable(v['name'], v['type'], context) self._add_variable('document', 'Document', context) self._add_variable('window', 'Window', context)
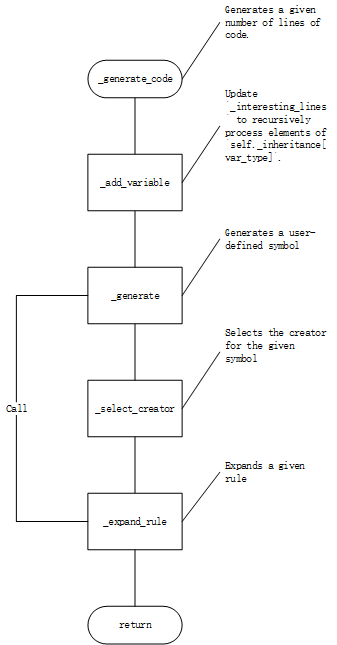
whilelen(context['lines']) < num_lines: tmp_context = context.copy() try: if (random.random() < self._interesting_line_prob) and (len(tmp_context['interesting_lines']) > 0): tmp_context['force_var_reuse'] = True lineno = random.choice(tmp_context['interesting_lines']) else: lineno = random.choice(self._all_nonhelper_lines) creator = self._creators['line'][lineno] self._expand_rule('line', creator, tmp_context, 0, False) context = tmp_context except RecursionError as e: print('Warning: ' + str(e)) ifnot self._line_guard: guarded_lines = context['lines'] else: guarded_lines = [] for line in context['lines']: guarded_lines.append(self._line_guard.replace('<line>', line)) return'\n'.join(guarded_lines)