AI基础
一、前言
之前对人工智能与机器学习等仅限于听说过这个名词,再深入一点就不懂了,正好前段时间看了公司的内部的人工智能(AI)入门课程,入门了下人工智能的基础,感叹了下,人工智能确实更加方便解决了之前难以解决的问题,这里将所学所思以博客的方式记录下。
二、概念
2.1 人工智能
2.1.1 人工智能概念
人工智能顾名思义就是研究如何模拟、延申并扩展人类智能的一门计算机科学。传统计算机编程可以解决“确定性问题”(最短距离计算,偏微分方程求解…),但对于不确定性问题(手写文字识别,垃圾邮件识别,听声辨人…),难以解决;人工智能所做的就是处理这些难以解决的问题。
2.1.2 研究人工智能的主要目的
促使计算机像人一样,
1)会听:语音识别
2)会看:图像、文字识别
3)会说:语音合成,人机对话
4)会思考:人机对弈,定理证明
5)会学习:知识表示
6)会行动:机器人,自动驾驶
2.1.3 人工智能在现实生活中的应用
人工智能的常见应用:推荐算法(知乎,浏览器,电商等);手写体识别(邮件地址,发票);人脸识别(门禁);医疗图像诊断与机器人手术; 电商虚拟客服;汽车无人驾驶与语音识别功能等。
安全中的应用:病毒文件检测;垃圾邮件检测;可疑域名检测;代码漏洞检测;异常行为检测……
2.2 机器学习
2.2.1 机器学习概念
通过已知数据、去学习数据中的规律与特征。并推广应用的未来新的数据上并做出判断或者预测。
2.2.2 机器学习基本流程
1)数据获取:自己采集;公开的数据集;(数据要具有代表性,广泛性)
2)数据预处理:归一化,离散化,去除共线性;(清洗数据,提高算法的效果)
3)特征工程:筛选显著特征,摒弃无用特征,生成高密度待训练向量;(数据和特征工程决定了机器学习的结果上限,算法只是让模型尽可能逼近上限)
4)机器学习(模型训练):选模型;调参优化;(不同模型以及不同参数,在同一数据集效果预测差异显著)
5)模型评估(效果预测):过拟合,欠拟合;精准率(P),召回率(F),推理加速、压缩,优化;模型部署;(高性能的模型对于数据具有较好的泛化性以及精确性)
2.2.3 机器学习算法分类
按学习方式分类可分为
| 学习方式 | 英文 | 描述 |
|---|---|---|
| 监督式学习 | Supervised Learning | 训练集目标:有标注; 如回归分析,统计分类。如房价预测与医学影像方面的应用,标签在学习过程中起到监督作用。 |
| 非监督式学习 | Unsupervised Leanring | 训练集目标:无标注;如聚类、GAN(生成对抗网络)。如客户分类与购物行为分析等方面的应用(没有标签主要是因为数据太乱、标注成本高、区分难度大等) |
| 半监督式学习 | Semi-supervised Leanring | 介于监督式与无监督式之间。部分数据集包含标签,对小部分数据起到监督作用。(通过已知标签的小部分数据,使用所有数据样本)。如文本分类与基于GPS的车道线检测等。 |
| 增强学习 | Reinforcement Leanring | 基于环境的反馈行动,通过不断与环境进行交互,通过试错的方式来获得最佳策略(收益最大化)。如优化营销与无人驾驶等。 |
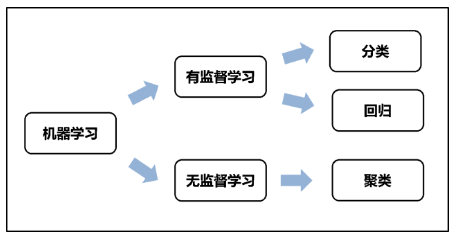
如果按照学习任务分类可分为
| 学习任务 | 英文 | 描述 |
|---|---|---|
| 分类 | Classification | 分类是预测一个标签 (是离散的),属于监督学习 |
| 回归 | Regression | 回归是预测一个数量 (是连续的),属于监督学习 |
| 聚类 | Clustering | 属于无监督学习 |
它们之间的关系如下
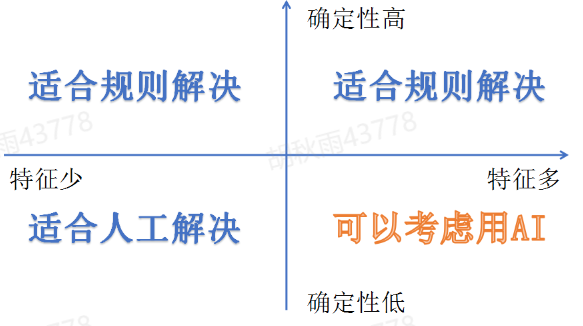
2.2.4 机器学习的使用场景
确定性高的一律用规则解决,也就是确定特征,这样保证判断的准确性。而当特征少时又不适合机器学习来解决,因为机器学习需要通过大量样本的训练提取特征,通过特征来做预测。所以机器学习适用于确定性低以及特征多的场景。
总的来说,机器学习适用于感知性的问题场景,而不适用于准确性的逻辑场景;适用于最优解获取复杂的问题场景,不适用于最优解获取简单的问题场景。
2.3 神经网络
2.3.1 神经网路的起源
介绍深度学习之前先了解下神经网络,深度学习是神经网络的一种组织形式。 神经网络来源于仿生学。人们希望机器能够像人一样会听、会算、会思考等等,那么,能否在计算机中,构造出一个人脑,成为了一个自然的想法。
起源:1981 年的诺贝尔医学奖,证明“可视皮层是分级的”
经过:在猫的后脑头骨上,开了一个3 毫米的小洞,向洞里插入电极,测量神经元的活跃程度;然后,他们在小猫的眼前,展现各种形状、各种亮度的物体。并且,在展现每一件物体时,还改变物体放置的位置和角度。经历了很多天反复的枯燥的试验,同时牺牲了若干只可怜的小猫,David Hubel 和Torsten Wiesel 发现了一种被称为“方向选择性细胞(Orientation Selective Cell)”的神经元细胞。当瞳孔发现了眼前的物体的边缘,而且这个边缘指向某个方向时,这种神经元细胞就会活跃。
结论:从原始信号摄入开始(瞳孔摄入像素 Pixels),接着做初步处理(大脑皮层某些细胞发现边缘和方向),然后抽象(大脑判定,眼前的物体的形状,是圆形的),然后进一步抽象,直至给出对物体****的判断(大脑进一步判定该物体是只气球)。
2.3.2 神经网络简单介绍
总结:神经网络的训练依靠反向传播算法:最开始输入层输入特征向量,网络层层计算获得输出,输出层发现输出和正确的类号不一样,这时它就让最后一层神经元进行参数调整,最后一层神经元不仅自己调整参数,还会勒令连接它的倒数第二层神经元调整,层层往回退着调整。经过调整的网络会在样本上继续测试,如果输出还是老分错,继续来一轮回退调整,直到网络输出满意为止。
BP神经网络里面的一些数学推导可以参考1.2 卷积神经网络基础补充,up主讲得比较清晰明了,他的其他视频也是值得学习的。
2.3.2.1 简化的两层神经网路分析
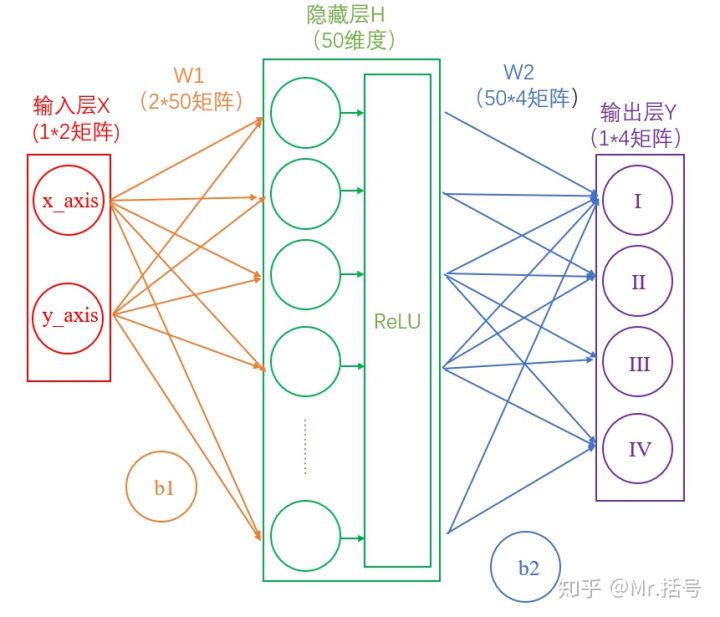
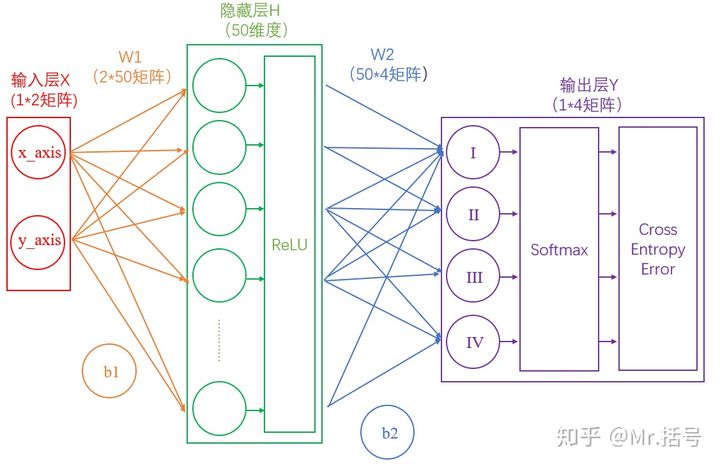
下面是两层神经网络的一种典型结构
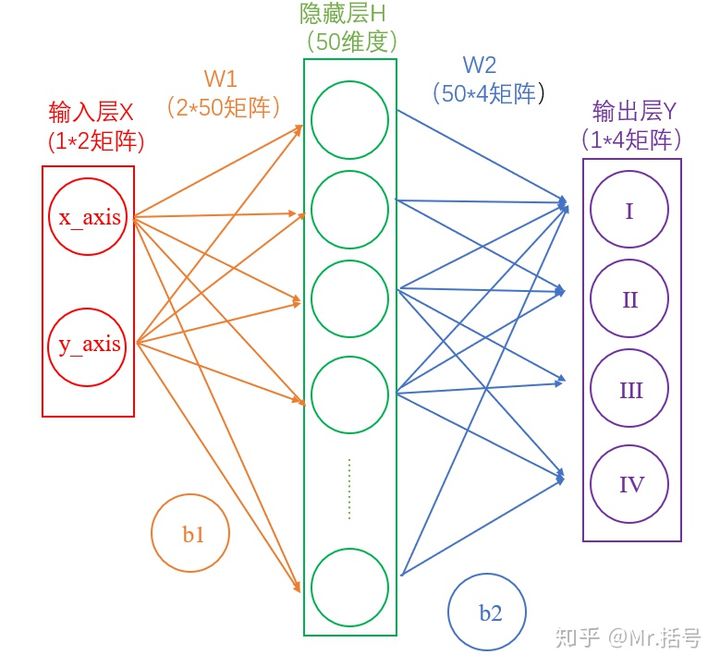
这里模拟了输入一个坐标,输出该坐标所在的象限(如(1,1)在第一象限),此时输入层代表我们的输入,也就是坐标(xy两个输入代表横纵坐标);输出层代表该坐标所在的象限(一共四个象限)。(其实这个例子并不是很合适,该例子完成可以通过确定判断来完成,忽略这个更优解法,从而得理解机器学习的概念也不失为一个优秀的思路,因为这个例子够简单)。
这里从输入层到隐藏层可以看作一个矩阵运算
1 | H = X*W1+b1 |
而从隐藏层到输出层,同样是通过矩阵运算进行的
1 | Y = H*W2+b2 |
通过上述两个线性方程的计算,我们就能得到最终的输出Y了,但是如果你还对线性代数的计算有印象的话,应该会知道:***一系列线性方程的运算最终都可以用一个线性方程表示***。也就是说,上述两个式子联立后可以用一个线性方程表达。对于两次神经网络是这样,就算网络深度加到100层,也依然是这样。这样的话整个过程就是线性的了(最终过程得到了一个线性方程),神经网络就失去了意义。
所以这里要对网络注入灵魂:激活层,激活层的作用就是为矩阵运算添加非线性结果。
2.3.2.2 激活函数
首先上一张图感受一下
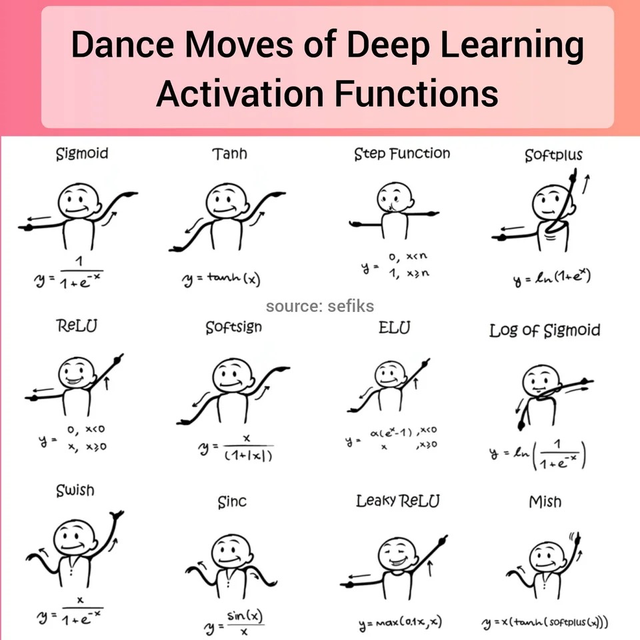
上面也提到了。激活函数为的作用主要是为矩阵运算添加非线性结果,常见的激活函数有三种,分别是阶跃函数、Sigmoid和ReLU。不要被奇怪的函数名吓到,其实它们的形式都很简单,如下图
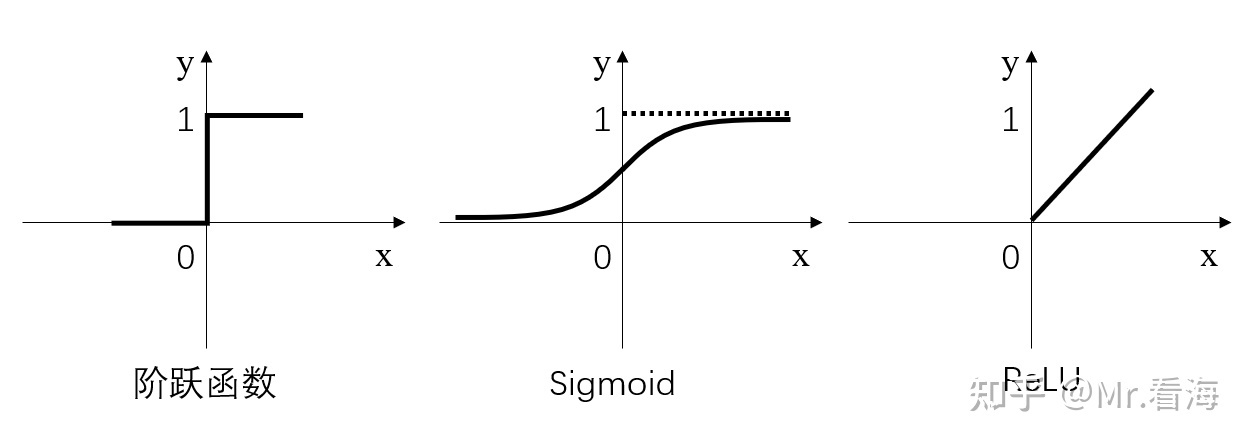
阶跃函数:当输入小于等于0时,输出0;当输入大于0时,输出1。
Sigmoid:当输入趋近于正无穷/负无穷时,输出无限接近于1/0。
ReLU:当输入小于0时,输出0;当输入大于0时,输出等于输入。
其中,阶跃函数输出值是跳变的,且只有二值,较少使用;Sigmoid函数在当x的绝对值较大时,曲线的斜率变化很小(梯度消失),并且计算较复杂;ReLU是当前较为常用的激活函数。
假如经过公式H=X*W1+b1计算得到的H值为:(1,-2,3,-4,7…),那么经过阶跃函数激活层后就会变为(1,0,1,0,1…),经过ReLU激活层之后会变为(1,0,3,0,7…)。需要注意的是,每个隐藏层计算(矩阵线性运算)之后,都需要加一层激活层,要不然该层线性计算是没有意义的。此时的神经网络变成了下图的形式。(需要注意的一点是,输入与w1可能有些点会被丢弃,这种做法同样参照仿生学,当我们的大脑同时接收到大量的信息时也会将消息分类为有用和无用的信息。这对机器学习很重要,因为不是所有的信息都是同样有用的,有些信息只是噪音。这就是激活函数的作用,激活函数帮助网络使用重要的信息,抑制不相关的数据点。)
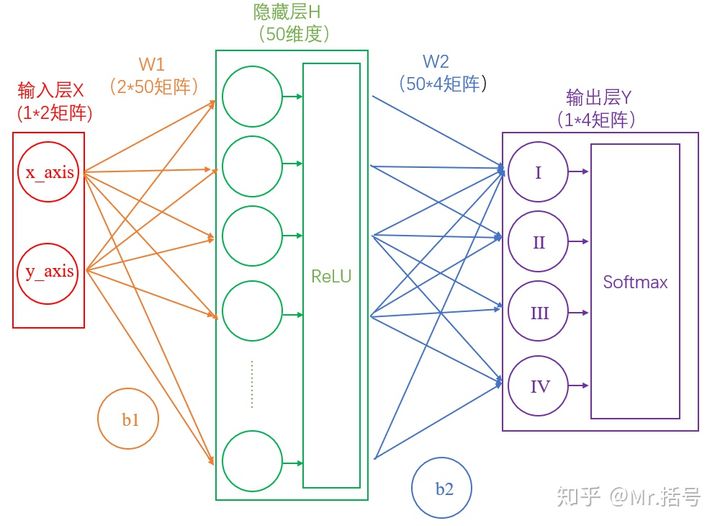
此时的输出层可能得到结果如(3,1,0.1,0.5)这样的矩阵,我们解读得到的数据,找到里面的3,得知大概率是在第一象限,但是这样做不够优雅,当然也可以对结果做简单的大小比较从而实现输出优化,但在人工智能领域,可以通过添加“Softmax”层达到输出“美化”的目的。得到了其对应的概率如(90%,5%,2%,3%),这样做不仅可以找到最大概率的分类,而且可以知道各个分类计算的概率值。具体计算公式为
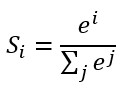
简单来说分三步进行:(1)以e为底对所有元素求指数幂;(2)将所有指数幂求和;(3)分别将这些指数幂与该和做商。
这样求出的结果中,所有元素的和一定为1,而每个元素可以代表概率值。此时的神经网络将变成如下图所示:
2.3.2.3 衡量输出的好坏(损失函数与评价指标)
通过Softmax层之后,我们得到了一个点处在四个象限的概率,但是要注意,这是神经网络计算得到的概率值结果,而非真实的情况。比如,Softmax输出的结果是(90%,5%,3%,2%),真实的结果是(100%,0,0,0)。虽然输出的结果可以正确分类,但是与真实结果之间是有差距的,一个优秀的网络对结果的预测要无限接近于100%,为此,我们需要将Softmax输出结果的好坏程度做一个“量化”。
一种直观的解决方法,是用1减去Softmax输出的概率,比如1-90%=0.1。不过更为常用且巧妙的方法是,求对数的负数。还是用90%举例,对数的负数就是:-log0.9=0.046。而求负数对数的过程也可以理解其为一个损失函数。而概率越接近100%,该计算结果值越接近于0,说明结果越准确,该输出叫做“交叉熵损失(Cross Entropy Error)”。我们训练神经网络的目的,就是尽可能地减少这个“交叉熵损失”。
然而考虑这样一种情况,如果最后的分类有人和男人,而男人是在人这个分类中的,最后所得的概率相加可能就不为1了,我们将这类问题称之为二分类问题,我们所用的输出优化函数常用的是sigmoid。而前面所举例的四个象限的问题称之为多分类问问题。
- 针对多分类问题(softmax输出,所有输出概率和为1)
- 针对二分类问题(sigmoid输出,每个输出节点之间互不相干)
2.3.2.4 反向传播与参数优化
上面的过程可以通过一句话总结:神经网络的传播都是形如Y=WX+b的矩阵运算;为了给矩阵运算加入非线性,需要在隐藏层中加入激活层;输出层结果需要经过Softmax层处理为概率值,并通过交叉熵损失来量化当前网络的优劣。
算出交叉熵损失后,就要开始反向传播了。其实反向传播就是一个参数优化的过程,优化对象就是网络中的所有W和b(因为其他所有参数都是确定的)。神经网络的神奇之处,就在于它可以自动做W和b的优化,在深度学习中,参数的数量有时会上亿,不过其优化的原理和我们这个两层神经网络是一样的。
举一个形象的例子,我们现在要靠饮食打造一个完美健康的身体。我们不断的调整糖类,脂肪,蛋白质及其他营养元素来实现我们的目的,这里的糖类,脂肪,蛋白质与其他营养元素就是上面提到的w1,b1,w2,b2。当我们摄入一次后,假设有个仪器可以查看我们的身体状态,发现这样的摄入比例并不能完美的使我们的身体变得更好,那么会将这次的结果向前传递,从而指导营养结构的优化,这就是梯度下降法。
反向传播可以帮助参数优化,从而使结果的概率更加接近百分之百。
2.3.2.5 迭代
神经网络需要反复迭代。如上述例子中,第一次计算得到的概率是90%,交叉熵损失值是0.046;将该损失值反向传播,使W1,b1,W2,b2做相应微调;再做第二次运算,此时的概率可能就会提高到92%,相应地,损失值也会下降,然后再反向传播损失值,微调参数W1,b1,W2,b2。依次类推,损失值越来越小,直到我们满意为止。
2.3.3 卷积神经网络
参考自零基础理解卷积神经网络 与从零开始实现卷积神经网络CNN及池化层详细介绍还有深度学习入门之池化层。
CNN(Convolutional Neural Network)。只要包含了卷积层的网络就被成为卷积神经网络
CNN的灵感的确来自大脑中的视觉皮层。视觉皮层某些区域中的神经元只对特定视野区域敏感。1962年,在一个Hubel与Wiesel进行的试验(视频)中,这一想法被证实并且拓展了。他们发现,一些独立的神经元只有在特定方向的边界在视野中出现时才会兴奋。比如,一些神经元在水平边出现时兴奋,而另一些只有垂直边出现时才会。并且所有这种类型的神经元都在一个柱状组织中,并且被认为有能力产生视觉。
卷积神经网络的学习过程借鉴了人类视觉系统的工作原理,当前已经被广泛应用于各个领域,主要包括人脸识别、车牌识别、物体识别、视频分析等涉及图像处理的场景,当然在自然语言处理等非图像处理领域也有应用。全连接深度神经网络(DNN)也可以用于图像处理任务,但是这类任务通常首选CNN,原因主要有两个:
一是图片很大,假设一张224x224组成的黑白图片,输入神经网络的特征维度为50176,假设神经网络只有一个隐藏层,其神经元个数为1024,那么就这么个简单的神经网络需要学习的参数就达到了51380224,超过千万,如果是3通道的彩色图片,则神经网络需要学习的参数量轻松过亿,这么庞大的参数量如果没有足够多的图片和计算资源的话,几乎很难训练。关键的是,在一张图片中并不是每一个像素都有用,通常能起到关键区分作用的是一些边角等局部特征,所以实际上我们并不需要这么多参数去拟合每一个像素。卷积神经网络能够自动从图片中提取到一些起区分作用的特征,在这之前,这些特征通常需要使用别的算法手动提取出来,然后再输入到支持向量机(SVM,Support Vector Machine)等分类模型中去。
二是待识别图片里面物体的位置会变化。假设我们需要判断一张宠物图片是猫还是狗,不管这只宠物位于图片的什么位置,从什么角度拍的,全身照还是大头照,模型要都能够准确识别出来它是猫还是狗,但是传统的神经网络没法适应这种变化,因为模型的每一个参数几乎与图片里面每一个像素位置联系了起来,图片内容一旦发生扭曲或者变形,都会导致模型输出变化很大。而卷积神经网络能够应对这种问题,因为它有参数共享架构及平移不变特性,因此CNN又被称为位移不变或者空间不变人工神经网络(SIANN,Shift Invariant Artificial Neural Networks)。
2.3.3.1 神经网络结构
CNN的工作流程是这样的:你把一张图片传递给模型,经过一些卷积层,非线性化(激活函数),池化,以及全连层,最后得到结果。就像我们之前所说的那样,输出可以是单独的一个类型,也可以是一组属于不同类型的概率。现在我们理解下各个层的作用。
2.3.3.2 卷积层-数学描述
假设我们将一个32x32x3的记录像素值的数组作为输入传入卷积层,想象卷积层中有一个手电筒照在了输入的左上角,且手电筒的光可以照到一个5 × 5的区域。现在,让我们想象这个手电筒照过了图片的所有区域。在机器学习术语中,这样一个手电筒被称为卷积核(或者说过滤器,神经元)(kernel, filter, neuron)。而它照到的区域被称为感知域(receptive field)。卷积核同样也是一个数组(其中的数被称为权重或者参数)。很重要的一点就是卷积核的深度和输入图像的深度是一样的(这保证可它能正常工作),所以这里卷积核的大小是5 × 5 × 3。
现在,让我们拿卷积核的初始位置作为例子,它应该在图像的左上角。当卷积核扫描它的感知域(也就是这张图左上角5 × 5 × 3的区域)的时候,它会将自己保存的权重与图像中的像素值相乘(或者说,矩阵元素各自相乘,注意与矩阵乘法区分),所得的积会相加在一起(在这个位置,卷积核会得到5 × 5 × 3 = 75个积)。现在你得到了一个数字。然而,这个数字只表示了卷积核在图像左上角的情况。现在,我们重复这一过程,让卷积核扫描完整张图片,(下一步应该往右移动一格,再下一步就再往右一格,以此类推),每一个不同的位置都产生了一个数字。当扫描完整张图片以后,你会得到一组新的28 × 28 × 1的数。((32 - 5 + 1) × (32 - 5 + 1) × 1)。这组数,我们称为激活图或者特征图(activation map or feature map)。
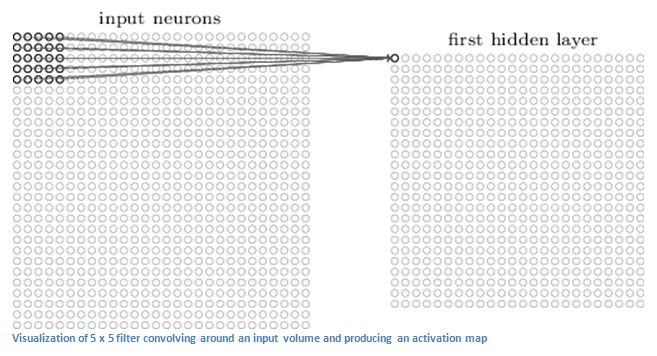
如果增加卷积核的数目,比如,我们现在有两个卷积核,那么我们就会得到一个28 × 28 × 2的数组。通过使用更多的卷积核,我们可以更好的保留数据的空间尺寸。
在数学层面上说,这就是卷积层所做的事情。
2.3.3.3 卷积层-更高角度
我们先了解一个概念:上面用卷积核与每个感知域重合会的得到一个数字,他们用来描述相似程度,数字越大,相似程度越高。也就是说,每一个卷积核都可以被看作特征识别器。现在我们尝试解释一下这个概念。
每一个卷积核都可以被看做特征识别器。我所说的特征,是指直线、简单的颜色、曲线之类的东西。这些都是所有图片共有的特点。拿一个7 × 7 × 3的卷积核作为例子,它的作用是识别一种曲线。(在这一章节,简单起见,我们忽略卷积核的深度,只考虑第一层的情况)。作为一个曲线识别器,这个卷积核的结构中,曲线区域内的数字更大。(记住,卷积核是一个数组)
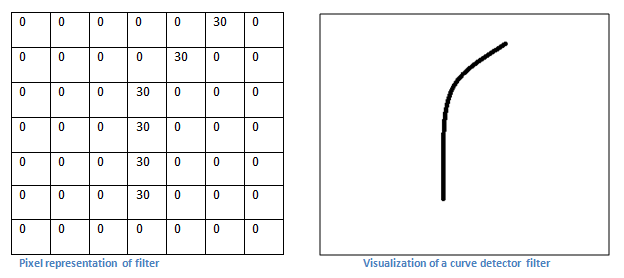
现在我们来直观的看看这个。举个例子,假设我们要把这张图片分类。让我们把我们手头的这个卷积核放在图片的左上角。
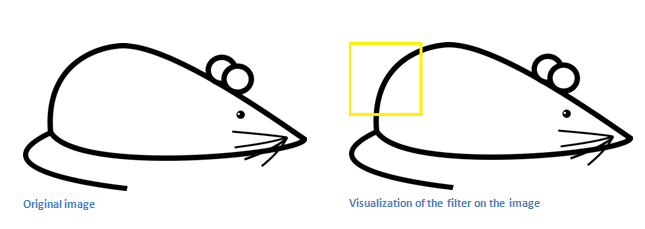
我们要做的事情是把卷积核中的权重和输入图片中的像素值相乘。(计算方式就是上面提到过的每个相同位置的数字相乘再相加)
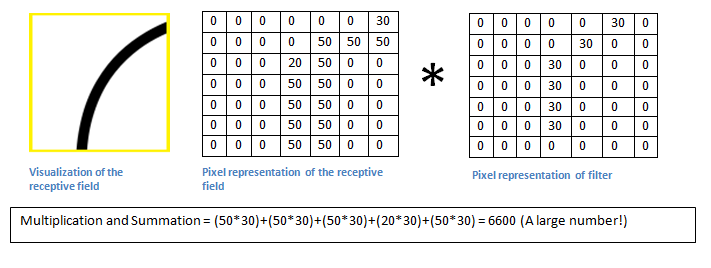
基本上,如果输入图像中有与卷积核代表的形状很相似的图形,那么所有乘积的和会很大。现在我们来看看,如果我们移动了卷积核呢?

可以看到,得到的值小多了!这是因为感知域中没有与卷积核表示的相一致的形状。还记得吗,卷积层的输出是一张激活图。所以,在单卷积核卷积的简单情况下,假设卷积核是一个曲线识别器,那么所得的激活图会显示出哪些地方最有可能有曲线。在这个例子中,我们所得激活图的左上角的值为6600。这样大的数字表明很有可能这片区域中有一些曲线,从而导致了卷积核的激活(也就是产生了很大的数值。)而激活图中右上角的数值是0,因为那里没有曲线来让卷积核激活(简单来说就是输入图像的那片区域没有曲线)。
但请记住,这只是一个卷积核的情况,只有一个找出向右弯曲的曲线的卷积核。我们可以添加其他卷积核,比如识别向左弯曲的曲线的。卷积核越多,激活图的深度就越深,我们得到的关于输入图像的信息就越多。
在文中提到的卷积核的主要目的是说明,是经过简化的。在下图中你会看到真正的经过训练后的神经网络中第一层卷积层中卷积核可视化后的样子。不管怎样,道理还是一样的。第一层的卷积核扫描整张网络,并在识别到相应特征时激活。

在传统的CNN结构中,还会有其他层穿插在卷积层之间。但总的来说,他们提供了非线性化,保留了数据的维度,有助于提升网络的稳定度并且抑制过拟合。一个经典的CNN结构是这样的:
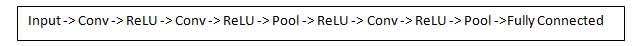
我们讲到了第一层卷积层的卷积核的目的是识别特征,他们识别像曲线和边这样的低层次特征。但可以想象,如果想预测一个图片的类别,必须让网络有能力识别高层次的特征,例如手、爪子或者耳朵。让我们想想网络第一层的输出是什么。假设我们有5个5 × 5 × 3的卷积核,输入图像是32 × 32 × 3的,那么我们会得到一个28 × 28 × 5的数组。来到第二层卷积层,第一层的输出便成了第二层的输入。这有些难以可视化。第一层的输入是原始图片,可第二层的输入只是第一层产生的激活图,激活图的每一层都表示了低层次特征的出现位置。如果用一些卷积核处理它,得到的会是表示高层次特征出现的激活图。这些特征的类型可能是半圆(曲线和边的组合)或者矩形(四条边的组合)。随着卷积层的增多,到最后,你可能会得到可以识别手写字迹、粉色物体等等的卷积核。
具体的卷积核可视化的信息,这个视频。
还有一件事情很有趣,当网络越来越深,卷积核会有越来越大的相对于输入图像的感知域。这意味着他们有能力考虑来自输入图像的更大范围的信息(或者说,他们对一片更大的像素区域负责)。
2.3.3.4 池化层
2.3.3.4.1 简单介绍
它实际上是一种形式的降采样。有多种不同形式的非线性池化函数,而其中“最大池化(Max pooling)”是最为常见的。它是将输入的图像划分为若干个矩形区域,对每个子区域输出最大值。直觉上,这种机制能够有效地原因在于,在发现一个特征之后,它的精确位置远不及它和其他特征的相对位置的关系重要。池化层会不断地减小数据的空间大小,因此参数的数量和计算量也会下降,这在一定程度上也控制了过拟合。通常来说,CNN的卷积层之间都会周期性地插入池化层。
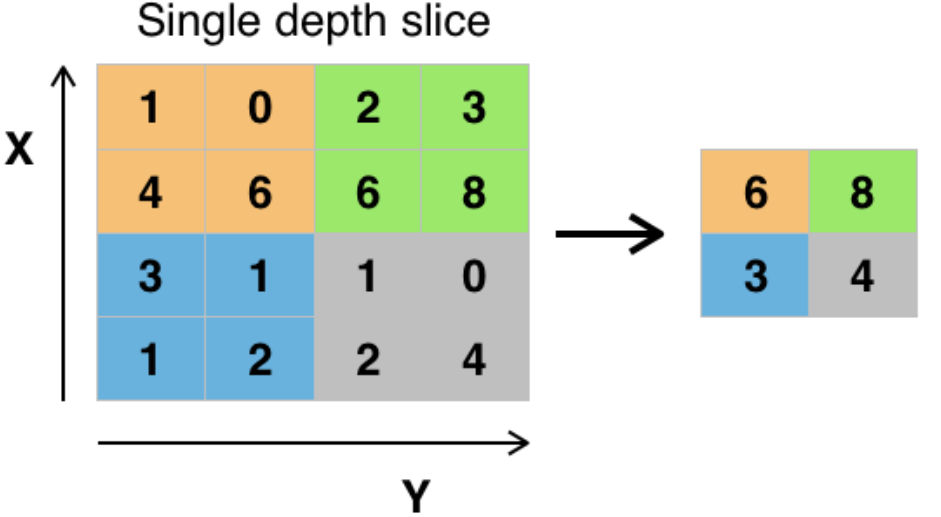
2.3.3.4.2 池化的作用
池化操作后的结果相比其输入缩小了。池化层的引入是仿照人的视觉系统对视觉输入对象进行降维和抽象。在卷积神经网络过去的工作中,研究者普遍认为池化层有如下三个功效:
1.特征不变性:池化操作是模型更加关注是否存在某些特征而不是特征具体的位置。其中不变形性包括,平移不变性、旋转不变性和尺度不变性。
平移不变性是指输出结果对输入对小量平移基本保持不变,例如,输入为(1, 5, 3), 最大池化将会取5,如果将输入右移一位得到(0, 1, 5),输出的结果仍将为5。对伸缩的不变形,如果原先的神经元在最大池化操作后输出5,那么经过伸缩(尺度变换)后,最大池化操作在该神经元上很大概率的输出仍是5.
2.特征降维(下采样):池化相当于在空间范围内做了维度约减,从而使模型可以抽取更加广范围的特征。同时减小了下一层的输入大小,进而减少计算量和参数个数。
3.在一定程度上防止过拟合,更方便优化。
- 池化层的常见操作包含以下几种:最大值池化,均值池化,随机池化,中值池化,组合池化等。这些池化操作的优劣可以参考深度学习入门之池化层,这里就不详细展开了。
2.3.3.5 全连层
到目前为止,我们已经识别出了那些高层次的特征。而卷积神经网络最后的画龙点睛之笔是全连层。
简单地说,这一层接受输入(来自卷积层,池化层或者激活函数都可以),并输出一个N维向量,其中,N是所有有可能的类别的总数。例如,如果你想写一个识别数字的程序,那么N就是10,因为总共有10个数字。N维向量中的每一个数字都代表了属于某个类别的概率。打个比方,如果你得到了[0 0.1 0.1 0.75 0 0 0 0 0 0.05],这代表着这张图片是1的概率是10%,是2的概率是10%,是3的概率是75%,是9的概率5%(小贴士:你还有其他表示输出的方法,但现在我只拿softmax(前面提到过的常用于结果优化输出的激活函数)来展示)。全连层的工作方式是根据上一层的输出(也就是之前提到的可以用来表示特征的激活图)来决定这张图片有可能属于哪个类别。例如,如果程序需要预测哪些图片是狗,那么全连层在接收到一个包含类似于一个爪子和四条腿的激活图时输出一个很大的值。同样的,如果要预测鸟,那么全连层会对含有翅膀和喙的激活图更感兴趣。
基本上,全连层寻找那些最符合特定类别的特征,并且具有相应的权重,来使你可以得到正确的概率。
2.3.3.6 训练与测试
在神经网络简单介绍的章节中已经提到了神经网路工作的整体过程,其中最常用的就是反向传播算法
在讲反向传播之前,我们得回头看看一个神经网络需要什么才能工作。我们出生的时候并不知道一条狗或者一只鸟长什么样。同样的,在CNN开始之前,权重都是随机生成的。卷积核并不知道要找边还是曲线。更深的卷积层也不知道要找爪子还是喙。等我们慢慢长大了,我们的老师和父母给我们看不同的图片,并且告诉我们那是什么(或者说,他们的类别)。这种输入一幅图像以及这幅图像所属的类别的想法,是CNN训练的基本思路。
反向传播可以被分成四个不同的部分。前向传播、损失函数、反向传播和权重更新这四个过程是一次迭代。程序会对每一组训练图片重复这一过程(一组图片通常称为一个batch)。当对每一张图片都训练完之后,很有可能你的网络就已经训练好了,权重已经被调整的很好。
最后,为了验证CNN是否工作的很好,我们还有另一组特殊的数据。我们把这组数据中的图片输入到网络中,得到输出并和标签比较,这样就能看出模型的表现如何了。
2.3.3.7 总结
这里只是对神经网络做了一个简单的介绍,并没有进行一个全面的描述。有关非线性化、池化层和网络的超参数(比如卷积核的大小,步长,边缘处理)并没有在这里中讨论。还有网络结构、数据归一化、梯度消失、Dropout、初始化技巧、非凸优化、偏移、损失函数的选择、数据增强、标准化方法,以及有关运算的考虑、反向传播的优化等等我们都还没有讨论。
2.4 深度学习
2.4.1 深度学习概念
深度学习是机器学习的一种,其概念源于人工神经网络的研究,含多个隐藏层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。研究深度学习的动机在于建立模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本等
2.4.2 深度学习与传统机器学习优劣比较
深度学习(Deep Learning)VS 传统机器学习(Machine Learning),优劣比较:
1、端到端 VS 分阶段:DL学习能力更强,对特征工程要求更低
2、数据依赖:DL广泛的假设空间,依赖更广泛的样本
3、算力依赖:DL对计算能力要求极高,GPU必不可少
4、可解释性差:DL判断原理类似黑箱,经典的获得可解释性的方法,是通过ML模拟DL模型(蒸馏),进而获取可解释性;
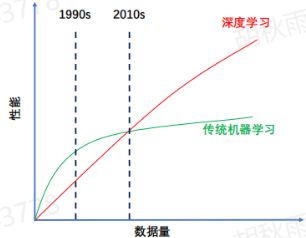
2.4.3 深度学习兴起的关键——数据+算力
伴随数据爆炸,传统机器学习无法充分利用庞大的数据进一步提升效果,而与之相比,深度学习刚好可以尽量充分的利用数据。大量的数据和参数空间需要算力支撑,新硬件的兴起弥补了通用处理器算力增长的乏力,为深度学习的发展和繁荣奠定了基础。然而,深度学习对数据和算力的需求,远未达到“充分”;模型参数增长量亦远超硬件计算速度增长了一次,深度学习仍有进一步发展空间。
2.4.4 深度学习简介
借用公司大佬提炼的十个问题,与国外大佬发布的相关的视频,大家可以更详细的了解深度学习。
问题1:神经网络由什么构成?——神经元(数字的容器,内含激活值) + 连接(连接方式+权重)
问题2:为何分层,我们期待中间层做什么?——提取更“高阶”的特征(输入点-图形短边-笔画-输出数字)
问题3:中间的“连线”是在干什么?——让层与层之间,相互影响(eg:正向传播为例,上一层决定下一层)
问题4:这个网络,参数量有多少大——可调,以两个隐藏层均为16个神经元为例,共13002个参数
问题5:层与层之间,如何相互影响——“确定”的函数运算;前一层推算后一层的值,又称“正向传播”
问题6:“正向传播”这么复杂,编程困难么?——调用函数库,3行python代码!
问题7:从零开始到在客户侧部署一个模型,有哪些步骤?——网络设计、模型训练、模型部署
问题8:深度学习相对与传统机器学习算法,主要优势?——学习能力更强,对特征工程要求更低
问题9:深度学习繁荣的关键(前提)是什么?——大量的数据,充分的算力
问题10:深度学习的经典应用范围,有哪些?——计算机视觉(CV),自然语言处理(NLP)
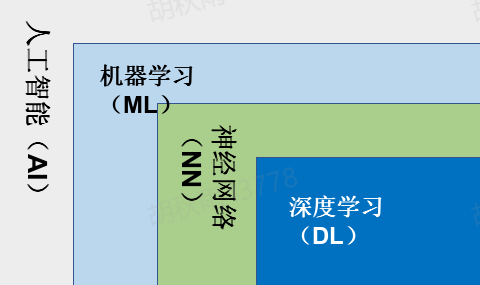
2.5 人工智能、机器学习、神经网络与深度学习的概念与它们之间的关系
人工智能:模拟、延申并扩展人类智能的一门计算机科学。通俗点讲就是让计算机可以替代人类或超越人类去做社会生活中的事儿。
机器学习:通过已知数据、去学习数据中的规律与特征。并推广应用的未来新的数据上并做出判断或者预测。(数据和特征工程决定了机器学习的结果上限,算法只是让模型尽可能逼近上限。也就是说源数据是很重要的)。
神经网络:来源于仿生学,使计算机模仿生物神经网络的形式来解决实际问题。
深度学习:深度学习是机器学习的一种,其概念源于人工神经网络的研究,含多个隐藏层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。研究深度学习的动机在于建立模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本等。通俗点讲就是高算力得到的可以进行更多层的数据处理,以神经网络为基石完成更艰巨的任务。
三、机器学习实践
3.1 TensorFlow
3.1.1 环境安装
3.1.1.1 前言
这里环境的安装可以参考该链接。在按照该链接安装tensorflow之前,简单介绍下tensorflow笔者在安装时不清楚的基础概念,方便大家对这个安装过程更加了解。
tensorflow的安装一般可以分为正常安装以及anaconda安装。anaconda是为机器学习以及深度学习提供便利,致力于简化软件包管理系统和部署,拥有超过1400个软件包。简单来说,anaconda可以方便机器学习以及深度学习环境搭建,为每个生产环境提供独立的执行环境,这种设计理念有点类似于docker,docker就以尽可能节约资源的方式将服务分隔开,相互独立互不干扰。当然anaconda的优势还不止这些。
当然正常安装tensorflow也是可以的,参考
https://github.com/tensorflow/tensorflow
https://www.tensorflow.org/install/gpu
这两种方式笔者均进行了尝试,正常安装需要安装各种驱动以及配置环境变量,比较麻烦,还是推荐使用anaconda进行安装,包括后面的pytorch也可以使用anaconda进行搭建。
如果使用anaconda安装直接参考下面的步骤即可,也可以参考上面的链接。
3.1.1.2 anaconda安装
下载安装anaconda,并配置国内源
1 | conda config --remove-key channels |
3.1.1.3 TensorFlow安装
这里注意软件后面指定的版本均可以通过conda search --full --name xx来指定,如conda search --full --name python就枚举了python的各个版本。
1 | conda create -n tensorflow python==3.9 # 这里的tensorflow可以改为其他字符串,如fa1lr4in-tf,python的版本也可以通过conda search --full --name python进行枚举,这个步骤的目的是配置虚拟环境342 |
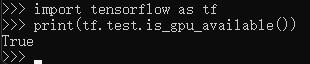
验证是否安装成功
1 | import tensorflow as tf |
之后使用tensorflow时直接通过启动器启动anaconda,然后执行conda activate tensorflow进入anaconda的tensorflow虚拟环境就可以了。
3.1.2 基础知识
3.1.2.1 张量(Tensor)
TensorFlow 内部的计算都是基于张量的,因此我们有必要先对张量有个认识。张量是在我们熟悉的标量、向量之上定义的,详细的定义比较复杂,我们可以先简单的将它理解为一个多维数组:
1 | 3 # 这个 0 阶张量就是标量,shape=() |
TensorFlow 内部使用tf.Tensor类的实例来表示张量,每个 tf.Tensor有两个属性:
- dtype: Tensor 存储的数据的类型,可以为tf.float32、tf.int32、tf.string…
- shape: Tensor 存储的多维数组中每个维度的数组中元素的个数,如上面例子中的shape
3.1.3 简单的demo
这里参考读懂一个 demo,入门机器学习,这里的demo要做的工作是从图片中识别手写体的数字。类似于识别验证码的功能。这里用到的数据源为MNIST(Mixed National Institute of Standards and Technology database) 。
3.1.3.0 MNIST介绍
MNIST是美国国家标准与技术研究院收集整理的大型手写数字数据库,包含 60,000 个示例的训练集以及 10,000 个示例的测试集。数据集中的训练集 (training set) 由来自 250 个不同人手写的数字构成,其中 50%是高中学生,50% 来自人口普查局 (the Census Bureau) 的工作人员。测试集(test set) 也是同样比例的手写数字数据。
其他细节参照官网
3.1.3.1 处理输入
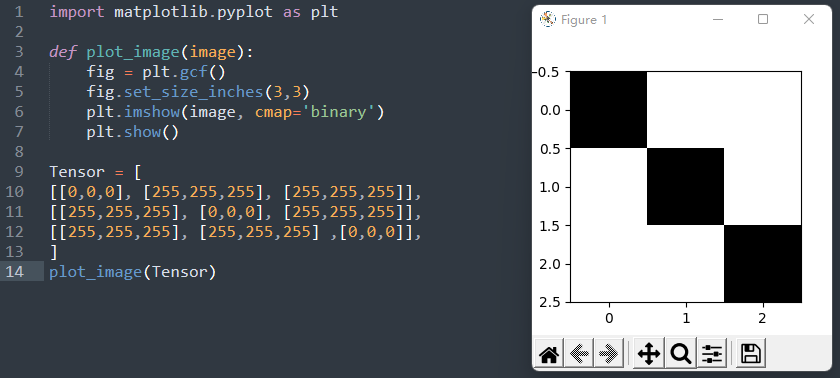
要实现识别图片中数字的功能,首先要注意的一个点就是TensorFlow如何识别图片。常见软件识别图片的方法可能是二进制格式,也可能是base64编码,还有可能是其他方式等等。而在TensorFlow,图片将被解析为上面提到的张量,下面是将张量转换为图片的一段demo,生成了像素 3*3 、背景为白色、对角线为黑色的图片。
1 | import matplotlib.pyplot as plt |
3.1.3.2 模型与神经网络
模型是个函数,这里面内置了很多参数,这些参数的值会直接影响模型的输出结果。有意思的是这些参数都是可学习的,它们可以根据训练数据来进行调整来达到一组最优值,一个训练有素的模型可以提供从输入到所需输出的精确映射。(从代码可以看出tensorflow对每个过程进行了高度封装,从而使使用者无需内部实现逻辑而开箱即用,大大降低了使用门槛,但是如果要深入研究仍需学习源码)。
在这里可以拿到demo代码。
1 | import tensorflow as tf |
这里对编写的模型进行训练与测试,执行5次整个过程的结果如下。

而执行两百次后测试结果如下

可以看到得到的结果并没有明显的优势,可能需要对模型进行优化。(优化算法,损失函数,激活函数,layer层等等都可能影响效果)
3.2 Pytorch
3.2.1 环境安装
1 | conda create -n pytorch python==3.9 |
安装完毕,之后执行
1 | import torch |
如果返回True,证明安装没有问题。但是笔者这里返回的是False,遂对错误进行了排查,参考了该链接。
首先查看pytorch与cuda的版本对应关系
1 | import torch |
经过查找资料,在该链接中下载了如下版本的torch,将其下载
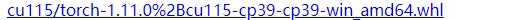
之后进行修复,命令为
1 | pip uninstall torch |
再次进行测试
1 | import torch |
返回True,表示支持GPU加速
3.2.2 基础知识
3.2.2.1 Pytorch Tensor的通道排序
Pytorch Tensor的通道排序:[batch, channel, height, width]。
比如6000张彩色的32x32像素的图像,Tensor形状为(6000, 3, 32, 32)
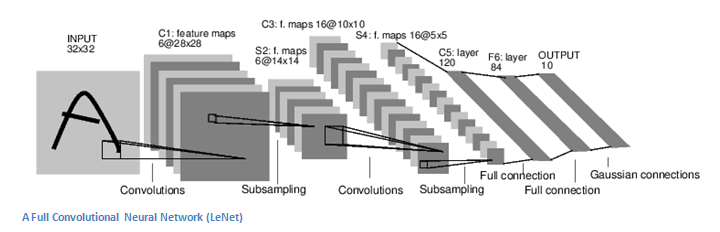
3.2.2.2 Lenet
参考自卷积神经网络之Lenet
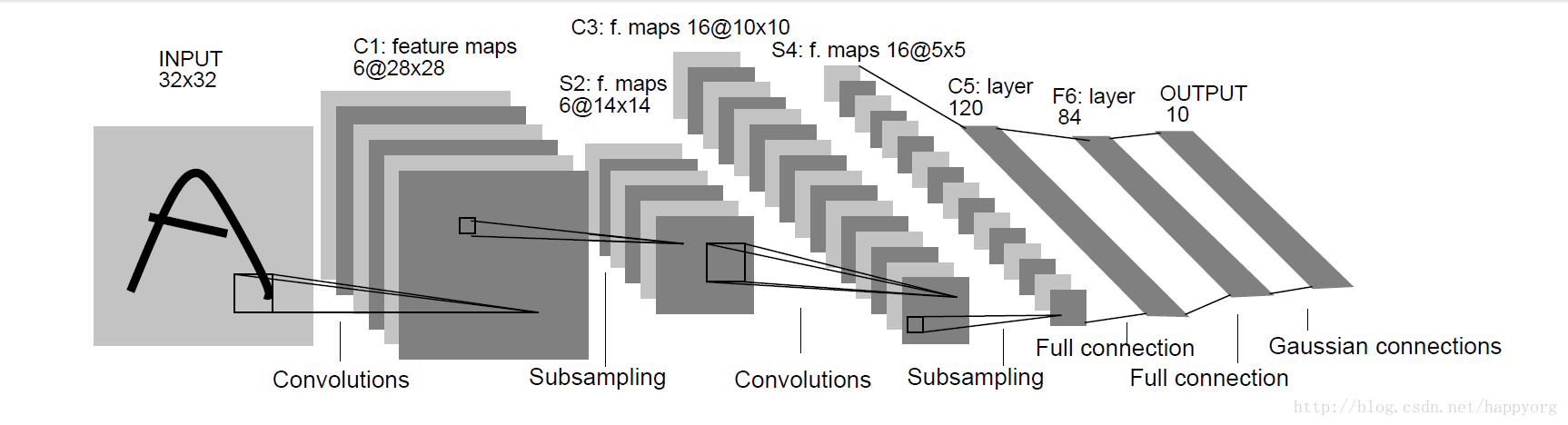
Lenet 是一系列网络的合称,包括 Lenet1 - Lenet5,由 Yann LeCun 等人在 1990 年《Handwritten Digit Recognition with a Back-Propagation Network》中提出,是卷积神经网络的 HelloWorld。
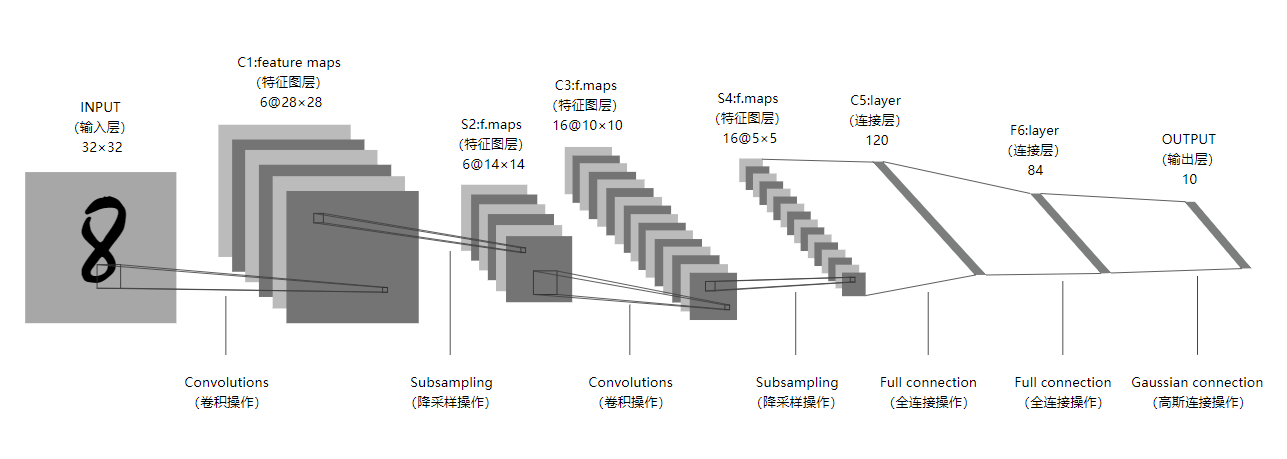
Lenet是一个 7 层的神经网络,包含 3 个卷积层,2 个池化层,1 个全连接层。其中所有卷积层的所有卷积核都为 5x5,步长 strid=1,池化方法都为全局 pooling,激活函数为 Sigmoid,网络结构如下:
重制后的插图如下
3.2.3 简单demo
3.2.3.1 前言
这里采用的官方的一个图像分类的demo,用来识别图像中的物体。里面用到了卷积神经网络的知识。参考了2.1 pytorch官方demo(Lenet)这个视频。以及pytorch图像分类篇:pytorch官方demo实现一个分类器(LeNet)这篇文章。官方demo链接:TRAINING A CLASSIFIER。代码参考链接: https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/pytorch_classification/Test1_official_demo
在看代码之前,最好要保证对上面的基础有一定的了解,这样才不会对里面的基础概念一头雾水,当有了一定基础后,发现这个代码确实是比较基础的,目的就是为了了解pytorch搭建一个简单卷积神经网络的方式(实际上就是调API,还是那句话,真正的革新并不是拿别人已经封装好的东西,要了解里面的数学原理,思考哪些东西可以进行优化,当然可能很少有人可以做到吧,大部分人也就是拿着现成的API来训练模型)。
该demo中包含了三个文件
- model.py——定义LeNet网络模型
- train.py——加载数据集并训练,训练集计算损失值loss,测试集计算accuracy,保存训练好的网络参数
- predict.py——利用训练好的网络参数后,用自己找的图像进行分类测试
3.2.3.2 model.py
初始化以及定义神经网络正向传播的过程
1 | import torch.nn as nn # These are the basic building blocks for graphs: ref: https://pytorch.org/docs/stable/nn.html |
3.2.3.3 train.py
1 | import torch |
3.2.3.4 train.py(GPU)
1 | # # 使用下面语句可以在有GPU时使用GPU,无GPU时使用CPU进行训练 |
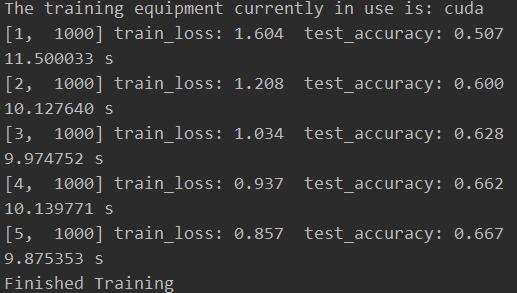
这里为了方便观察,我将输出的周期调整到1000次,观察一下二者的区别
gpu
cpu
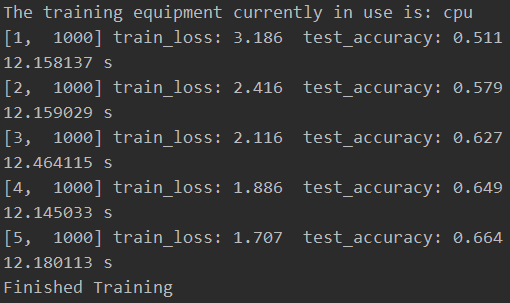
比较令人费解的是二者的时间差距并不明显,按理说gpu应该比cpu快很多倍的。笔者十分确信它们就是cpu与gpu的结果,因为我在跑训练的时候观察任务管理器确实是分别使用了cpu与gpu的资源。(笔者这里使用的cpu为5900x,gpu为3060,不晓得是什么问题)
3.2.3.5 predict.py
1 | import torch |
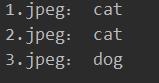
这里测试了三张图片,其中两张识别错误了,说明这个状态字典还是比较年轻啊=)
测试结果



3.2.3.6 遇到的问题
1 iter.next为什么有两个返回值与其作用()
在笔者分析代码的过程中,train.py使用到了iter函数,最开始我认为它与正常的python迭代器别无二致,但观察第二行代码发现,它的next方法存在两个返回值,这勾起了我的兴趣,调试到对应代码行,查看它的类型,果然是重新实现了的。
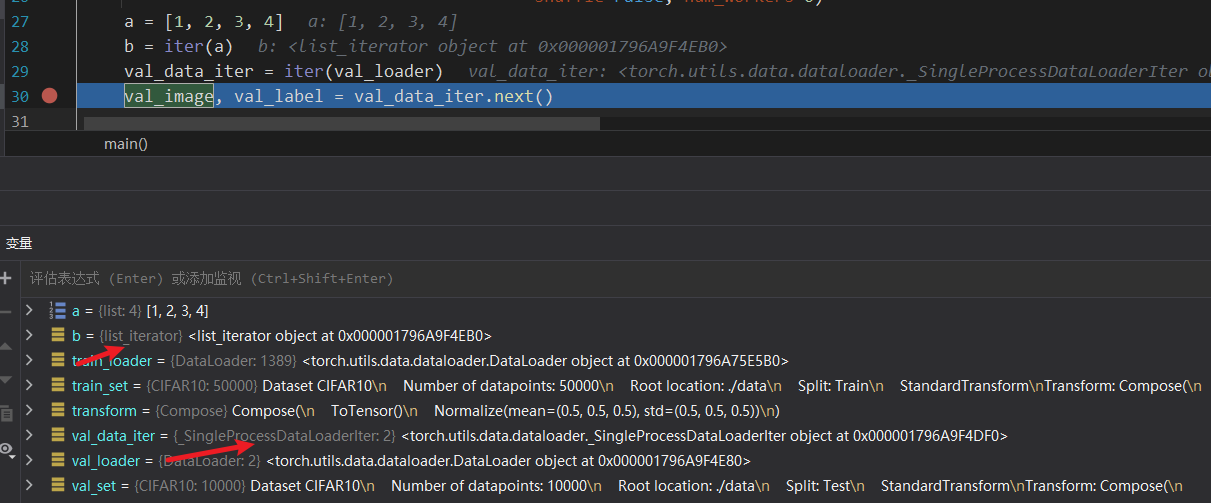
python内置的迭代器一般情况是list_iterator,而这里则是_SingleProcessDataLoaderIter,看下pytorch源码
1 | class _SingleProcessDataLoaderIter(_BaseDataLoaderIter): |
额,只返回了data,做下测试。
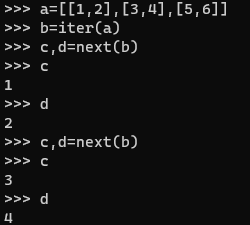
原来返回值可以存在多个,我是个智障。。。。。。。。
四、总结
本篇文章简单介绍了人工智能、机器学习、神经网络与深度学习的含义以及其内部包含的一些基础性的概念,并通过一个demo了解了下卷积神经网络的简单实现。算是一个由AI初学者从工业界的视角简单记录了下学习AI的过程。
这次的AI学习之旅源于公司内部的技术分享,学习的过程中发现,原来学科交叉可以碰撞出如此剧烈的思维火花,如“卷积神经网络”就集合了生物学,数学与计算机学。让机器具有深度学习的能力,目前在CV领域达到开枝散叶的成功,对人的日常生活影响确实是巨大的。技术确实是丰富了生活,但是我却不由得联想到了公民隐私泄露相关的的问题,软件商非法获取手机的权限:获取相册权限通过CV模型来描绘用户画像,或者剪切板以及录音等权限通过nlp模型直接定位用户喜好,这可能是科技发展的另一面吧。不过机器学习带给我的震撼还是无与伦比的,说不定之后的智能机器人真的可以解放大量的生产力,或者我们想象不到的更多事情。
五、参考
- 神经网络15分钟入门!足够通俗易懂了吧
- 【官方双语】深度学习之神经网络的结构 Part 1 ver 2.0
- Anaconda、TensorFlow安装和Pycharm配置详细教程!
- 2021年Windows下安装GPU版本的Tensorflow和Pytorch
- 读懂一个 demo,入门机器学习
- pytorch download
- 解决torch.cuda.is_available()返回结果为False
- 零基础理解卷积神经网络
- 从零开始实现卷积神经网络CNN
- 池化层详细介绍
- 深度学习入门之池化层
- 深度学习在图像处理中的应用(tensorflow2.4以及pytorch1.10实现)
- 1.2 卷积神经网络基础补充
- 2.1 pytorch官方demo(Lenet)
- 卷积神经网络之Lenet
- pytorch图像分类篇:pytorch官方demo实现一个分类器(LeNet)