垃圾回收的算法与实现
前言
这篇文章与其说是blog,不如说是reading notes。里面大部分内容都参考自《垃圾回收的算法与实现》。另一部分则是笔者对v8的官方blog和源码进行分析得出。作者的文字内容逻辑清晰,通俗易懂,笔者受益匪浅,相信每个人阅读此书都有种醍醐灌顶的感觉。笔者仅仅是将书中的内容理解并归纳,方便日后应用可以找到理论依据,也是将自己的学习历程记录下来。我会用尽量精炼且逻辑清晰的语言描述一些概念,而不是用长篇累牍的描述与书中相同的东西,那毫无意义,这样做的目的是为了自己在多年后看到这篇文章仍然可以快速回忆起里面的内容,也希望可以帮助大家快速的掌握GC相关的知识。
here we go!
算法篇
一些定义
对象:对象是 GC 的基本单位;对象由头(header)和域(field)构成,头(header)描述了对象的特征并可能设有一些flag数据结构,而域(field)则表示对象的数据部分。
mutator:相当于进程,在运行的过程中会对内存进行操作,可以产生或销毁对象,也是GC的目标。
堆:GC的主要目标,对象的分配和GC都在这里进行。$heap_start + HEAP_SIZE == $heap_end
活动对象/非活动对象:能通过 mutator 引用的对象称为“活动对象”。不能通过mutator 引用的对象称为“非活动对象”。
chunk:对象所占用的那块空间。
根(root):是指向对象的指针的“起点”部分。寄存器、调用栈、全局变量空间这些都是根,因为他们可以指向活动对象。
【评价标准】吞吐量:处理同样大小的堆需要的时间,时间越小吞吐量越大。
【评价标准】最大暂停时间:GC会使 mutator 暂停执行,所有次GC中时间消耗最久的即为最大暂停时间,该指标影响了人机交互体验。
【评价标准】堆使用效率:可以解释为完成同样的任务占用的堆空间越多,堆使用效率越低。
【评价标准】是否利用缓存优势:具有引用关系的对象在堆中如果相距比较近,则可以提高在缓存中读取到想利用的数据的概率,令 mutator 高速运行。这叫做利用了缓存优势。
三大经典算法:分别指GC标记-清除算法(Mark Sweep GC),引用计数法(Reference Counting),GC复制算法(Copying GC)。其他众多GC算法都是从这三种算法衍生出来的。
GC标记 -清除算法(Mark Sweep GC)
定义
GC 标记 - 清除算法由标记阶段和清除阶段构成。标记阶段会将所有活动对象都做上标记。而清除阶段会将没有标记的对象(即非活动对象)进行内存回收。(John McCarthy 1960年发布)
实现
1 | // mark_sweep:标记-清除算法,分为标记阶段和清除阶段 |
评估
优点
实现简单:算法简单,实现容易,与其他算法的组合也简单。
缺点
碎片化:空闲链表里面的chunk地址空间一般是不连续的,造成了比较多的内存碎片。这样当分配大对象时即使空闲空间的总大小>=大对象的大小也无法给大对象分配空间。分配速度较慢:GC 标记 - 清除算法使用了空闲链表的数据结构,这样在分配时需要遍历空闲链表来进行chunk的分配。而GC复制算法和GC标记-压缩等搜索型算法则不需要,它们的空闲空间是连续成块的,需要时将其切割即可。与写时复制技术不兼容:Linux在Fork进程时有“读时共享,写时复制”的机制。而在GC标记-清除算法的标记阶段会对每个对象进行进行标记,这样相当于对头进行了数据的写入,造成了无谓的内存复制。
实际上缺点1和2都是空闲链表这个数据结构的问题,缺点三则是标记flag设置的问题。
优化措施
多个空闲链表(multiple free-list)
总体来说就是将之前的单个空闲链表变为多个空闲链表,每个空闲链表装固定大小的空闲chunk,解决的是分配速度较慢的问题。
一般mutator 很少会申请非常大的chunk。为了应对这种极少出现的情况而大量制造空闲链表,我们给chunk大小设定一个上限,chunk如果大于等于这个大小就全部采用一个空闲链表处理。举个例子——如果设定chunk大小上限为 100 个字,那么准备用于 2个字、3 个字、……、100 个字,以及大于等于 101 个字的总共 100 个空闲链表就可以了。
1 | // new_obj:分配对象的阶段,根据要分配对象的大小从对应的空闲链表中去取。 |
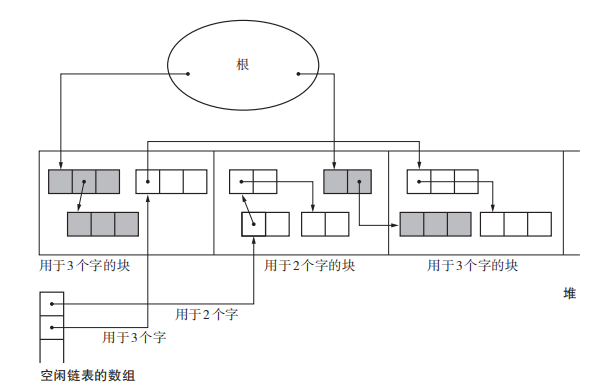
BIBOP法(Big Bag Of Pages)
将堆切成若干块,每块堆空间里面存放的对象大小相同。下图第一部分和第三部分存放的都是三个字大小的对象,而第二部分存放的都是两个字大小的对象。但是有个问题,它不能完全消除碎片化——比方说在第一部分就有空闲chunk,而第二部分还是有活动对象,这样就产生了碎片化,不过可以一定程度上缓解之前的无序状态。
位图标记法(bitmap mark)
经典的GC标记-清除算法通过在对象的头中设置flag位来实现标记状态的判定,上面也已经提到了这与写时复制技术不兼容,所以我们可以维护一个表格来管理所有对象的标记状态。这个表格就叫做 “位图表格” 。利用这个位图表格进行标记的行为称为 “位图标记”。
【优点】与写时复制技术兼容:比较好理解,这种方式标记修改的只是位图表格,并没有修改对象。
【优点】清除操作更高效:由于维护了位图表格,清除阶段取消标志位的过程直接通过遍历位图表格取消置位即可。
【注意】当堆不同时,offest也不同,这时就需要不同的位图表格来服务每一个堆。
1 | // mark:标记阶段,没什么好说的,只是之前标记了对象头,现在标记在位图表格中了。 |
延迟清除法(Lazy Sweep)
延迟清除法是缩减因清除操作而导致的 mutator 最大暂停时间的方法。在标记操作结束后,不进行清除操作,而是如其字面意思一样让它“延迟”,通过“延迟”来防止 mutator 长时间暂停。它没有空闲链表这个数据结构。
1 | // new_obj:这里先使用快速方式从堆的中间部分往下寻找空闲对象,如果找不到。执行完整的GC标记-清除算法,如果仍然找不到则代表堆中没有适合大小的空闲块(因为这里没有空闲链表的数据结构)。这样确保整个堆已经被完整的遍历一遍了。说白了第一次lazy_sweep是快速搜索,第二次lazy_sweep是全量搜索。 |
这种情况下可以减少最大暂停时间,但不是绝对。
如果某次标记阶段结束后的堆如下——当$sweeping在空闲对象周围时可以马上获得chunk,此时可以减少 mutator 的暂停时间。而一旦$sweeping在活动对象周围时则将长时间获取不到空闲chunk,之后第二次进行了完整的标记-清除的过程反而使 mutator 的暂停时间增加。
最大暂停时间较长的问题可以通过增量式垃圾回收方式解决(三色标记法)。
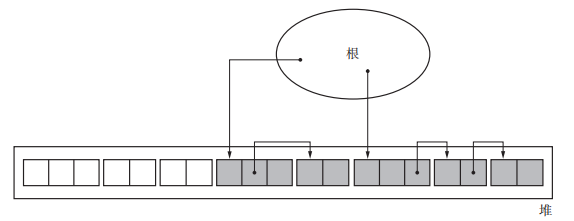
引用计数法(Reference Counting)
定义
引用计数法中引入了“计数器”的概念,也就是有多少程序引用了这个对象(被引用数)。(George E. Collins 1960年发布,Harold McBeth 1963解决了循环引用的问题)
实现
创建对象
1 | // new_obj:当新创建一个对象时,计数器由0增加到1。 |
更新引用计数
1 | // update_ptr:两步操作,一是进行计数器的增减,二是更新指针指向的对象。这里需要注意的就是需要先加后减,原因是为了处理 *ptr 和 obj 是同一对象时的情况,当先减后加时,obj的引用计数可能变为0被释放了,此时再进行加就找不到对象了(因为已经被回收了)。 |
引用计数法有两个特点
- 引用计数法的垃圾回收是实时的。
- 可以说将内存管理和mutator同时运行。
评估
优点
立即回收垃圾:垃圾可以实时的被回收掉,并将chunk链接到空闲链表中供对象申请最大暂停时间短:其他GC方式都有一个专门的GC阶段,而引用计数法的GC和mutator是同时运行的。没必要沿指针查找:这个是引用计数法的特点,不同于搜索型算法,引用计数法没有遍历内存的过程。
缺点
计数器值的增减处理繁重:大多数情况下指针会频繁地更新。特别是有根的指针,这是因为根可以通过 mutator 直接被引用。计数器需要占用很多位:用于引用计数的计数器最大必须能数完堆中所有对象的引用数。假如我们用的是 32 位机器,那么就有可能要让 2 的 32 次方个对象同时引用一个对象。使堆使用效率降低了。实现烦琐复杂:引用计数的算法本身很简单,但事实上需要在每一处修改指针的代码出都加上增减计数器的逻辑。因为修改指针会发生的非常频繁,所以重写过程中很容易出现遗漏。引发bug或安全漏洞。循环引用无法回收:当两个对象互相引用时,各对象的计数器的值均为1。但是这些对象组并没有被其他任何对象引用。因此想一并回收这两个对象都不行。
虽然引用计数法有很多缺点,但是引用计数法只要稍加改良,就会变得非常具有实用性了。
优化措施
延迟引用计数法(Deferred Reference Counting)
该方式解决的是计数器值的增减处理繁重的问题。根的引用变化频繁是导致计数器增减处理繁重的重要原因之一。因此可以让根引用的指针变化不反映在计数器上。但可能发生对象仍在活动,但却被错当成垃圾回收的情况。于是,我们可以在延迟引用计数法中使用 ZCT(Zero Count Table)。ZCT 是一个表,它会记录计数器值在 dec_ref_cnt函数的作用下变为 0 的对象。由于计数器值为 0 的对象不一定都是垃圾,所以暂时先将这些对象保留。当ZST表爆满之后对ZST表进行处理来回收真正的垃圾。
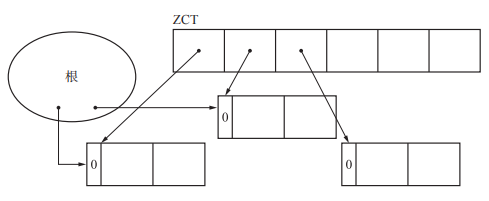
1 | // dec_ref_cnt:减计数器函数。当对象的计数器被减为0时将其放入ZST表中,如果ZST表爆满则调用scan_zct清理ZST表,让活动对象离开,回收垃圾。 |
【优点】延迟了根引用的计数,减轻了因根引用对计数器增减造成的负担。
【缺点】为了延迟计数器值的增减,势必造成垃圾不能马上得到回收。导致最大暂停时间延长。
Sticky引用计数法
该方式解决的是计数器需要占用很多位的问题。核心在于减少计数器的位宽。但减少位宽可能会出现数值溢出的现象。针对计数器溢出的问题,主要有两种方法来处理这个问题。
do nothing:不再处理该计数器溢出的对象。某对象计数器溢出正说明该对象较为重要,不易变为垃圾而被回收。使用GC标记-清除算法进行管理:可以使用GC 标记 - 清除算法来充当引用计数法的后援。大致思路就是将计时器全部清零(目的是为了模拟GC 标记 - 清除算法中的标记位),之后还是像GC 标记 - 清除算法一样,将活动对象的计数器+1,也就是让他非0,之后遍历整个堆回收非活动对象。这里的的 GC 标记 - 清除算法和之前的 GC 标记 - 清除算法主要有以下 3 点不同。
- 一开始就把所有对象的计数器值设为 0
- 不标记对象,而是对计数器进行增量操作
- 为了对计数器进行增量操作,算法对活动对象进行了不止一次的搜索
【优点】即使对象在计数器溢出后成了垃圾,程序还是能回收它。
【优点】可以回收循环的垃圾。
【缺点】吞吐量会降低:一是因为需要重置所有对象的计数器。二是由于这里的的 GC 标记 - 清除算法是进行计数器的增量,此时对象的索引也需要消耗一定的时间。
1位引用计数法(1bit Reference Counting)
1 位引用计数法解决的仍然是计数器需要占用很多位的问题。基于“一般的对象都很难被共有”的理论,可以得出一般的对象引用计数都为1。考虑到这一点,我们用 1 位来表示某个对象的被引用数是 1 个还是多个(即用 0 表示被引用数为 1, 1 表示被引用数>= 2,我们分别称以上 2 种状态为 UNIQUE 和 MULTIPLE),这样也能达到目的。
1 位引用计数法比较特殊的一点在于它使用指针来存放引用计数(正常引用计数法使用对象来存放,这里凭借四字节对齐最后两位不能利用的性质,可以将这个引用计数,也可以叫做flag放入指针来达到目的),这样当更新指针时只要将指针复制即可。
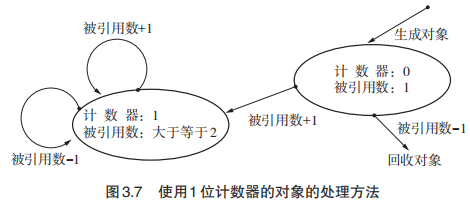
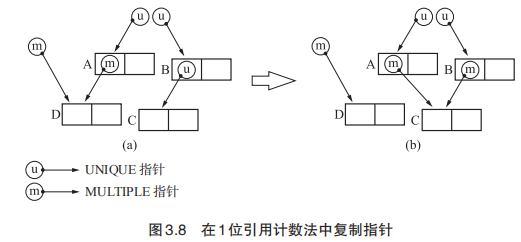
这里更新了之前由 A 引用 D 的指针,让其引用 C。这也可以看成是把由 B 到 C 的指针复制到 A 了。通过这项操作,两个指向 C 的指针都变成了 MULTIPLE 指针。
1 | // 上图的 A 的指针就是dest_ptr,B 的指针就是被复制的src_ptr。经过复制,两个指针都会set_multiple_tag,也就是都变成了 MULTIPLE 指针。 |
【优点】不容易出现高速缓存缺失:缓存作为一块存储空间,比内存的读取速度要快得多。如果要读取的数据就在缓存里的话,计算机就能进行高速处理;但如果需要的数据不在缓存里(即高速缓存缺失)的话,就需要读取内存,比较浪费时间。当某个对象 A 要引用在内存中离它很远的对象 B 时,以往的引用计数法会在增减计数器值的时候读取 B,从而导致高速缓存缺失。但由于1 位引用计数法不需要在更新计数器(或者说是标签)的时候读取要引用的对象,只是指针的复制过程,所以可以减少出现这种问题。
【优点】节省内存:毕竟只占用1位。
【缺点】无法处理计数器溢出的对象:和 Sticky 引用计数法一样,这个可能需要其他方式(比如GC标记-清除算法)辅助操作。
部分标记-清除算法(Partial Mark & Sweep)
首先提一句,这个算法看起来比较麻烦,但是原理还是很容易懂的,无非就是利用了一个队列存放可疑对象之后对可疑对象进行操作的过程。
上面用来兜底的GC 标记 - 清除算法由于以全部堆为对象导致效率很低。产生了很多无用的搜索。因此我们可以只对“可能有循环引用的对象群”使用 GC 标记 - 清除算法,对其他对象进行内存管理时使用引用计数法。像这样只对一部分对象群使用 GC 标记 -清除算法的方法,叫作“部分标记 - 清除算法”。
说白了,这个算法的目的就是为了找到循环引用的对象群并进行处理。
在部分标记 - 清除算法中,对象会被涂成 4 种不同的颜色来进行管理。每个颜色的含义如下:
- 黑(BLACK):绝对不是垃圾的对象(对象产生时的初始颜色)
- 白(WHITE):绝对是垃圾的对象
- 灰(GRAY):搜索完毕的对象
- 阴影(HATCH):可能是循环垃圾的对象。
具体实施方式是往头中分配 2 位空间,然后用00~11 的值对应这 4 个颜色,以示区分。这里用 obj.color 来表示对象 obj 的颜色。obj.color 取 BLACK、WHITE、GRAY、HATCH 中的任意一个值。
下面是具体步骤,以一个具体的例子进行描述
1、初始状态
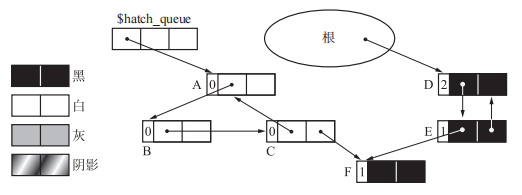
有循环引用的对象群是 ABC 和 DE,其中 A 和 D 由根引用。此外,这里由 C 和 E 引用 F。所有对象的颜色都还是初始状态下的黑色。
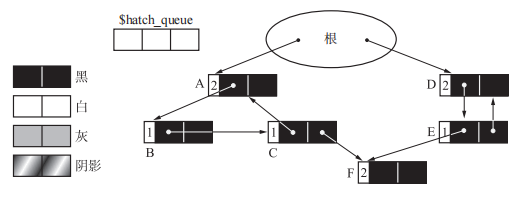
2、dec_ref_cnt
1 | // dec_ref_cnt:在进行减引用的操作时,如果该对象的引用计数不为0,将其颜色涂成阴影,并放入一个专门存放阴影对象的队列中。 |
在这步操作后堆状态如下。由根到 A 的引用被删除了,指向 A 的指针被追加到了队列($hatch_queue)之中。此外,A 被涂上了阴影。这个队列的存在是为了连接那些可能是循环引用的一部分的对象。被连接到队列的对象会被作为 GC 标记 - 清除算法的对象,使得循环引用的垃圾被回收。
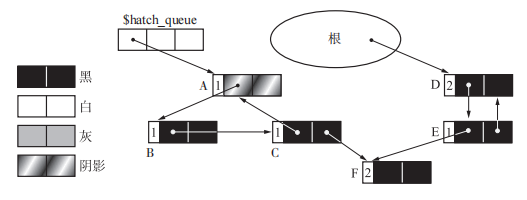
3、new_obj & scan_hatch_queue
1 | // new_obj:当可以分配时,对象就会被初始化成黑色。当分配无法顺利进行的时候,程序会通过 scan_hatch_queue() 函数搜索阴影队列去尝试回收垃圾。scan_hatch_queue() 函数执行完毕后,程序会递归地调用 new_obj() 函数再次尝试分配。 |
4、paint_gray
1 | // paint_gray:将选中的阴影对象及子对象(子对象颜色需为黑或阴影)涂灰,并将所有对象的子对象的引用计数减一, |
执行完成后大概如下图
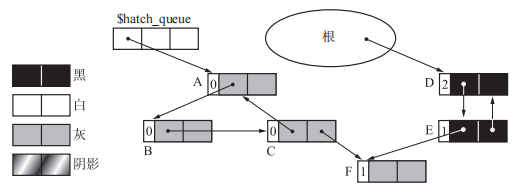
执行过程如下图
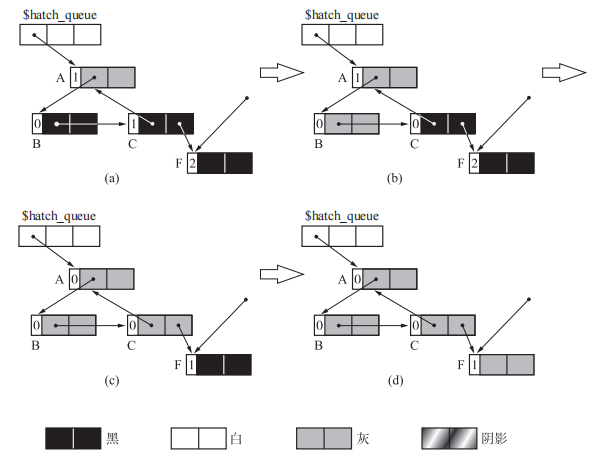
首先,在 (a) 中 A 被涂成了灰色。虽然程序对计数器执行了减量操作,但并不是对 A,而是对 B 的计数器进行了减量操作。下面在 (b) 中 B 也被涂成了灰色,不过这时程序并没有对 B 进行减量操作,而是对 C 进行了减量操作。在 (c) 中 C 被涂成灰色时,程序对 A 和 F 的计数器进行了减量操作。这样一来,A、B、C 的循环垃圾的计数器值都变成了 0。(d) 是 A、B、C、F 各个对象搜索结束后的样子。
部分标记 - 清除算法的特征就是要涂色的对象和要进行计数器减量的对象不是同一对象,据此就可以很顺利地回收循环垃圾。这样做的原因是为了明确这个阴影对象是否在环内,证明如下:
假如原始图如下
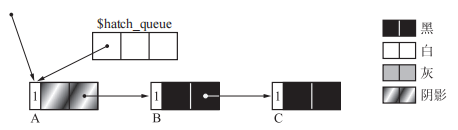
当要涂色的对象和要进行计数器减一的对象为同一对象时,过程如下
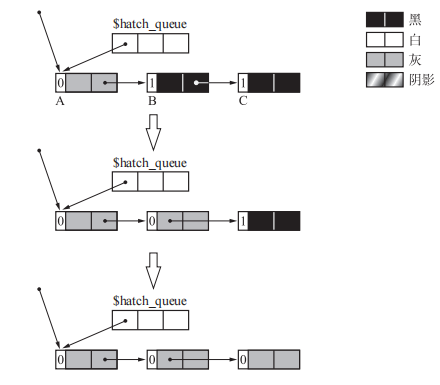
这样我们并不能通过A的引用计数直接确定该对象是否在环中。因为无论A是否成环,它的引用计数一直为0,所以无法对是否成环进行区分。而当我们计数器减一的对象在涂色对象之后时,我们可以很容易通过A的计数判断它是否是一个独立的环。
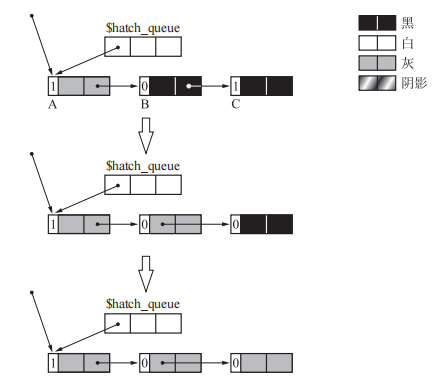
当搜索完 C 时对象 A 的计数器值为 1,所以 A 不能被回收。所以很明显这个并不是一个独立的环。在这之后,paint_black() 函数会把对象 A 到 C 全部涂黑,也会对 B 和 C 的计数器进行增量操作,这样对象就完全回到了原始的状态。
5、scan_gray
执行完 paint_gray() 函数以后,下一个要执行的就是 scan_gray() 函数。它会搜索灰色对象,把计数器值为 0 的对象涂成白色。
1 | // scan_gray:这个函数作用是为了操作灰色对象,如果灰色对象的引用计数为0则将其涂白,否则将其涂黑。 |
此时现场如下,不难看出,形成了循环垃圾的对象 A、B、C 被涂成了白色,而有循环引用的非垃圾对象 D、E、F 被涂成了黑色。
6、collect_white
1 | // collect_white,这个函数很简单,就是为了回收白色对象。但是这里我并不明白为什么还要把obj涂黑。 |
回收独立环后的对象如下。
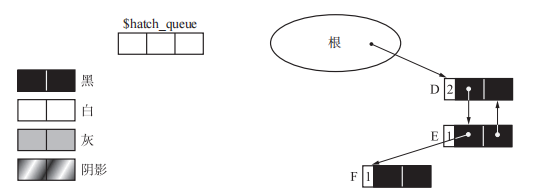
到这步已经完成了整个回收独立环的操作,大体步骤就是先将可疑对象挑出,然后遍历可疑对象挨个判断,判断方式为将子对象的引用计数减一,如果成环则环内的引用计数都会互相减为0,最终自身也会被减为0,也就是对象自己发起操作后又反馈改变了自身,这样就判断了环是否存在,之后就是回收环内对象的过程。而这个阴影队列的作用就在于假如这个阴影对象真的在环中我们无法找到他,就可以通过队列存放的指针指向这块空间。
【优点】吞吐量:聚焦于成环对象的搜索与清除,减少了其他无需索引对象的索引成本。
【缺点】吞吐量:还是吞吐量的问题,对队列中的候选垃圾处理较复杂。由于该算法对队列中每个对象进行了三次操作(mark_gray,scan_gray和collect_white),增加了内存管理所花费的时间。
【缺点】最大暂停时间增加:势必增加最大暂停时间的长度,毕竟会对队列对象进行操作。
GC复制算法(Copying GC)
定义
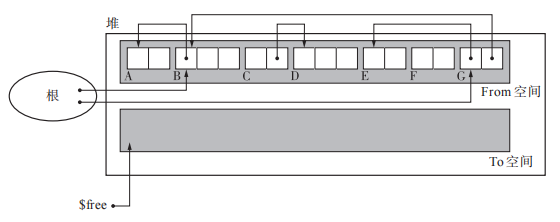
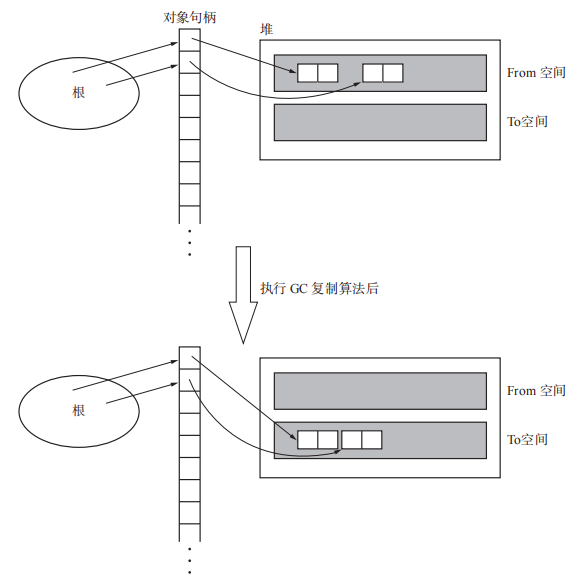
GC复制算法需要两块同样大小的空间,分别称为From空间和To空间。通过将From 空间的活动对象复制到To空间,再对From 空间和 To 空间互换来实现GC,此时新的From空间是一块干净的空间。(Marvin L. Minsky 1963发布)
实现
1 | // copying:将活动的对象从From空间copy进To空间,再对From 空间和 To 空间互换 |
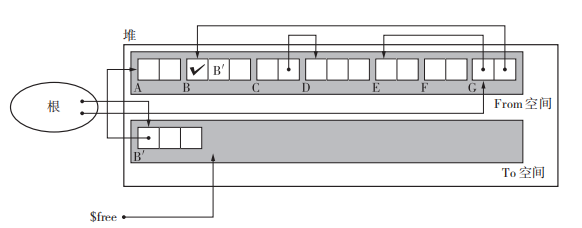
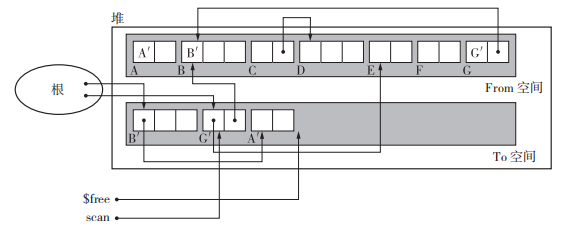
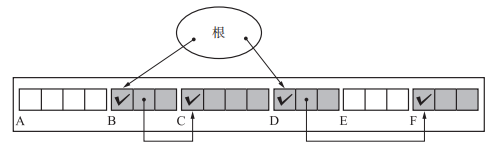
执行过程如下图,通过深搜的方式将根执行的活动对象依次由From空间拷贝到To空间。这里对号表示已经复制完成,对号后面的 BꞋ 表示的是forwarding指针,指向To空间。
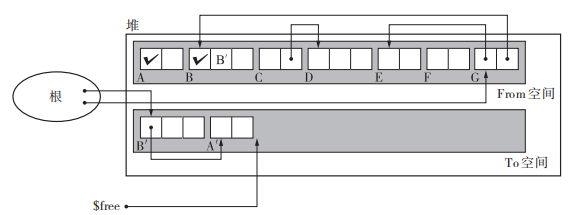
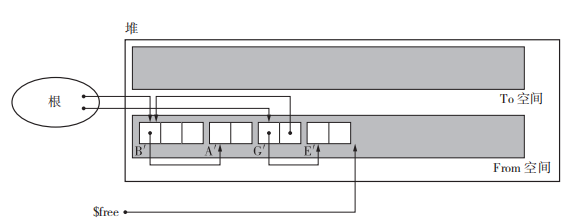
评估
优点
优秀的吞吐量:由于只需要遍历活动对象并清除整个堆的时间,所以它可以在较短时间内完成GC。可实现高速分配:GC 复制算法不使用空闲链表。这是因为空闲chunk是一个连续的内存空间。通过移动 $free 指针来分配内存。不会发生碎片化:由于GC复制算法具有“压缩”(把对象重新集中,放在堆的一端的行为)的性质,分配空间直接移动$free指针,就算$free前面的内存被释放了,GC之后又可以将活动对象“压缩”。与缓存兼容:在 GC 复制算法中有引用关系的对象会被安排在堆里离彼此较近的位置。这可以使 mutator 执行速度加快。
缺点
堆使用效率低:GC 复制算法把堆二等分,只能利用其中的一半来安排对象,浪费空间。不兼容保守式GC算法:GC 复制算法必须移动对象重写指针,而保守式GC的性质决定了它不允许移动对象。递归调用函数:复制某个对象时要递归复制它的子对象。因此带来额外的处理负担。相比起递归算法,迭代算法能更高速地执行 。
优化措施
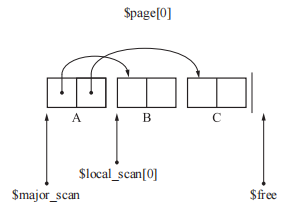
Cheney的GC复制算法
解决的是递归调用函数的问题。核心在于使用迭代方式遍历复制,但是使用了广搜的方式,但是没有充分利用缓存的便利——有引用关系的对象不相邻。
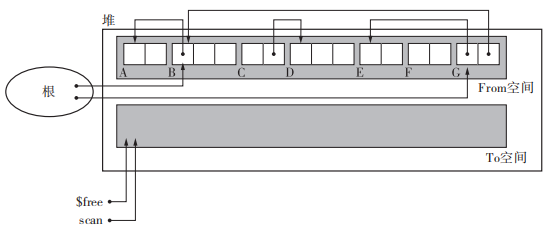
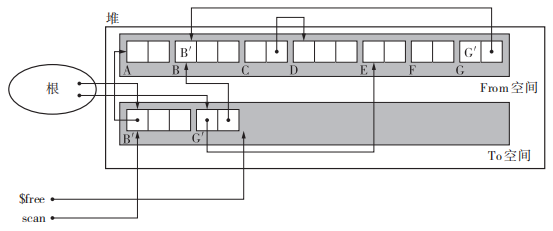
1 | // 将 scan 和 $free 的两个指针初始化。scan 是用于搜索复制完成的对象的指针。$free 是指向chunk开头的指针, |
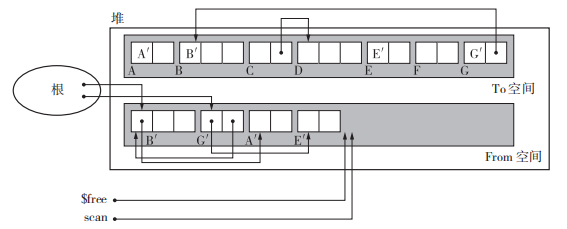
使用了$scan 和 $free。首先复制所有从根直接引用的对象,在这里就是复制 B 和 G。$scan指向当前正在搜索的对象,$free指向空闲chunk的开头。复制的过程中$scan与 $free一般中间会有一部分对象,我们知道这些对象都是活动对象,并按照先入先出(FIFO)的方式进行操作(这样把堆兼用作队列正是 Cheney 算法的一大优点,不用特意为队列留出多余的内存空间就能进行搜索。)。最后复制完成后$scan与 $free会重合。
【优点】递归方式遍历子对象减轻了调用函数的额外负担和栈的消耗。特别是拿堆用作队列,省去了用于搜索的内存空间的步骤。
【缺点】具有引用关系的对象是相邻的才能充分利用缓存的便利。在该算法中使用了广搜致使引用对象并不相邻是比较可惜的一点。
近似深度优先搜索方法
解决的仍然是递归调用函数的问题,对Cheney 的 GC 复制算法进行了缓存上的优化,Cheney 的 GC 复制算法由于在搜索对象上使用了广度优先搜索,因此存在“没法沾缓存的光”的缺点。近似深度优先搜索方法可以解决这个问题。
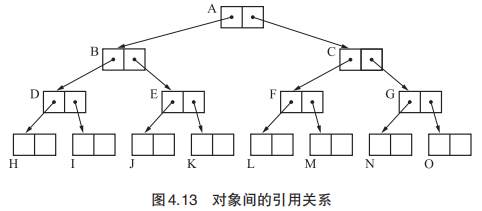
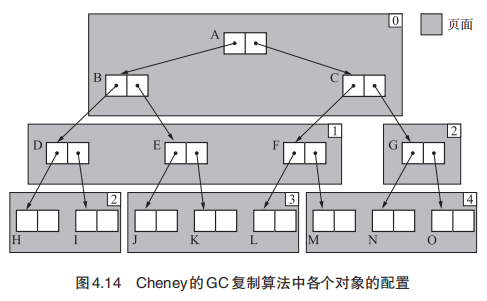
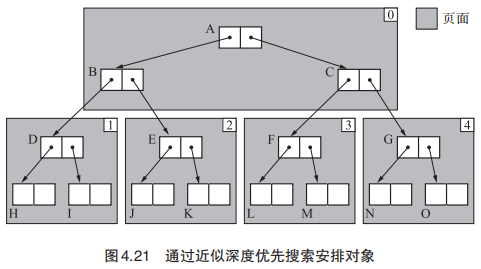
当使用近似深度优先搜索算法时,如果一个对象被安排在页面开头时,直接搜索该对象的子对象。概念也比较好理解,广搜的过程中对临近对象使用深搜。
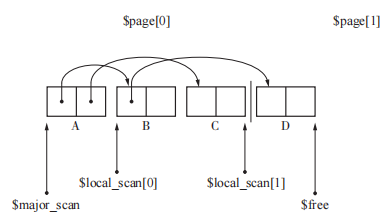
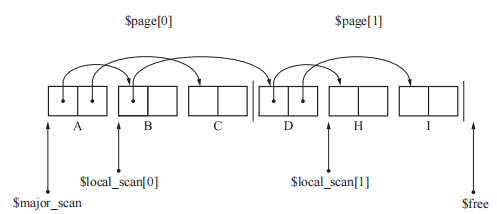
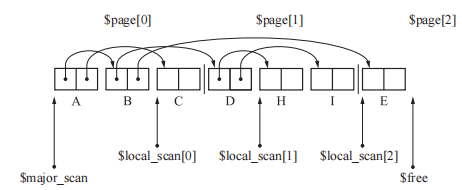
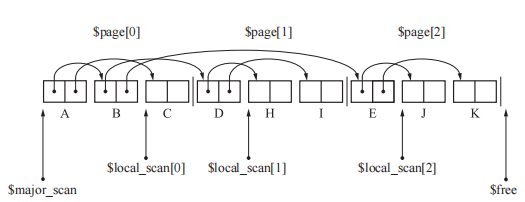
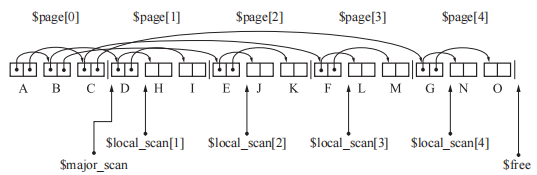
多空间复制算法
GC 复制算法最大的缺点是只能利用半个堆。如果把堆由分成 2 份改为分成 10 份,其中的2 块空间执行 GC 复制算法。其他8份空间执行其他GC算法,就可以提高堆使用效率。
1 | // multi_space_copying:这里将堆 N 等分,每次To空间和From空间都会后移,其余的对象使用GC标记-清除算法。 |
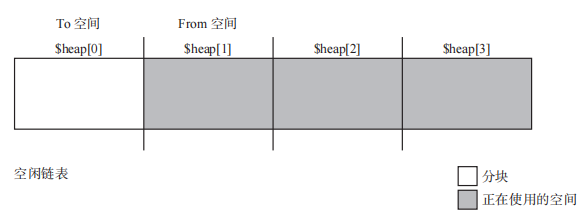
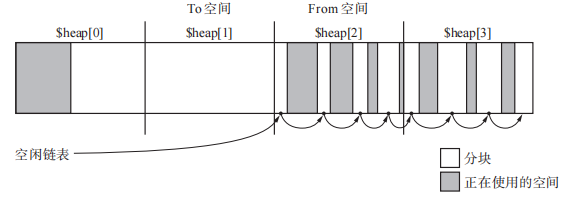
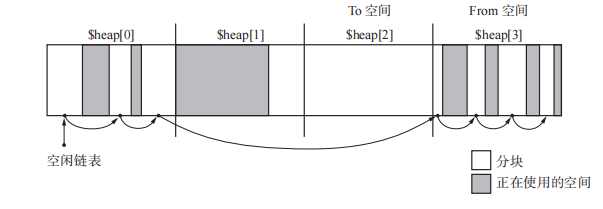
【优点】提高了堆使用效率。
【缺点】由于引入了GC-标记清除算法,虽然提高了堆使用效率,但是分配耗费时间、chunk碎片化等问题也会出现。
GC标记-压缩算法(Mark Compact GC)
定义
GC 标记 - 压缩算法由标记阶段和压缩阶段构成。首先,这里的标记阶段和 GC 标记 - 清除算法时提到的标记阶段完全一致。接下来搜索数次堆来进行压缩。压缩一是可以利用缓存优势,二是可以减少内存碎片,也无需牺牲半个堆。
实现
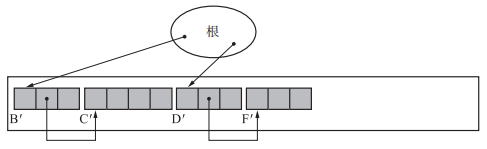
首先是经典的Lisp2算法,Lisp2 算法在对象头提供了 $forwarding 指针的空间。 $forwarding 指针指向要移动位置的地址。这也是这个算法的一个劣势(每个对象都要额外占用一个forwarding 指针)。
为什么每个对象都要额外占用一个forwarding 指针?(由于GC复制算法中使用了两块空间,将数据完成后再将原From空间的数据段选出一部分当作$frorwarding指针,毕竟当复制过程完毕后原From空间的对象也失去了意义。设置$frorwarding的目的是当有指针指向原From空间的原活动对象时,可以使用$forwarding指针将该指针索引到To空间的活动对象中。而Lisp2算法没有类似于To空间这样的复制空间,而且流程是先设置$forwarding指针再去移动对象,所以之前的对象内容需要进行保留,如果仍使用其数据段会覆盖对象原本的内容(GC复制算法随便修改之前对象的内容,之后都会被全部清空),所以需要额外占用一个forwarding 指针存放要移动到的位置)。
整体流程
Lisp2算法的压缩阶段并不会改变对象的排列顺序,只是缩小了它们之间的空隙,把它们聚集到了堆的一端。他和GC复制算法有个很大的区别就是GC复制算法是对每个对象都进行复制对象,对象指针修改,forwarding指针修改,处理完一个对象再处理下一个对象。而Lisp2算法则是分为三个阶段,每个阶段都处理所有对象。
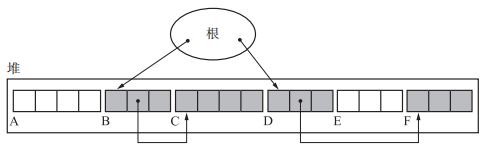
压缩阶段
1 | // compaction_phase:Lisp2的压缩阶段由三个阶段组成:(1)设定 forwarding 指针; (2)更新指针; (3)移动对象 |
评估
优点
堆利用率高:一是因为压缩,使得其基本没有碎片化问题。二是相对于GC复制算法,不需要舍弃半个堆,而可以在整个堆中安排对象。堆使用效率几乎是 GC 复制算法的 2 倍。
缺点
吞吐量较低:以Lisp2算法为例,整个过程需要对整个堆进行三次搜索。执行该算法所花费的时间是和堆大小成正比的。
优化措施
Two-Finger算法
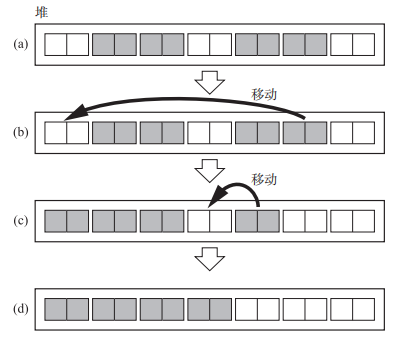
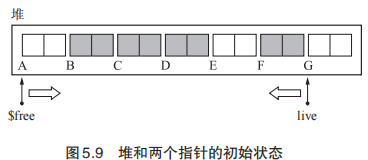
Two-Finger算法一是需要所有对象大小一致 ,二是无需forwarding 指针空间 。由以下 2 个步骤构成。(1)移动对象 。 (2)更新指针 。实际上相当于两根手指分别从堆首和堆尾向中间逼近,将后面的活动对象放在前面去,由于对象大小一致,所以这样移动没有任何后顾之忧)
实现如下
1 | // move_obj:移动对象,使用$free 和 live 两个指针从两端向正中间搜索堆。$free 是用于寻找非活动对象(目标空间)的指针,live 是用于寻找活动对象(原空间)的指针。当两个指针相遇时证明已完成压缩。 |
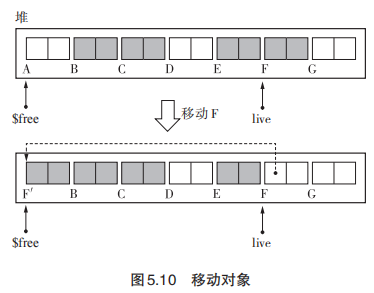
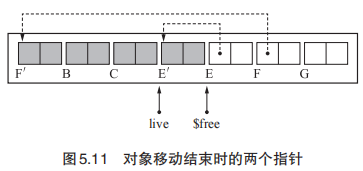
【优点】无需要额外的空间存放 forwarding 指针,相比于 Lisp2 算法提高了堆使用效率。
【优点】由于优化了更新 forwarding 指针的步骤,所以可以少搜索一次整个堆。
【缺点】不能利用引用对象相邻的缓存优势,这样操作完全不能保证引用对象相邻。
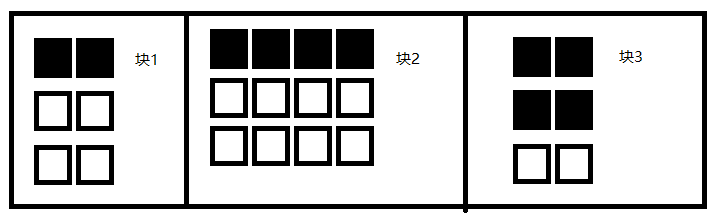
【缺点】要求所有对象的大小必须一致。不过可以结合BiBOP 法克服这个问题——将同一大小的对象安排在同一个块里,之后对每个块应用 Two-Finger 算法。如下,每个块的活动对象都在它的起始位置
表格算法
这个又是个看起来很恐怖其实也比较好理解的算法。
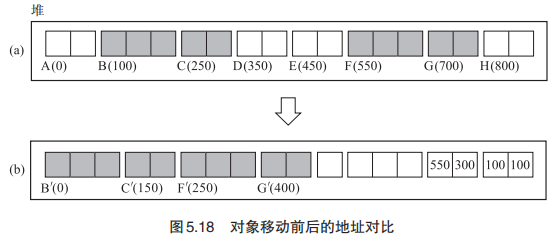
表格算法:(1)对象群一起移动。(2)使用了间隙表格来代替forwarding 指针。
它通过以下 2 个步骤来执行压缩。(1)移动对象(群)以及构筑间隙表格(break table)。(2)更新指针。
基本思路就是将之前的一个对象一个对象向前移动的方式改为移动对象群,并通过间隙表格存储代替forwarding 指针。间隙表格第一项存储的是被移动对象的起始位置,第二项存储的是要向前移动的长度。(比如下面图片的(100,100)就代表B的起始位置为100,向前移动100到 BꞋ)。之后的指针移动也是同理,只不过由原来的通过forwarding 指针索引改编为通过间隙表格索引了。
1 | // move_obj:该伪代码只包含了移动对象(群)的操作,而构筑间隙表格(break table)使用了slide_objs_and_make_bt函数实现,伪代码实现比较麻烦,所以下面文字图片方式进行解释。 |
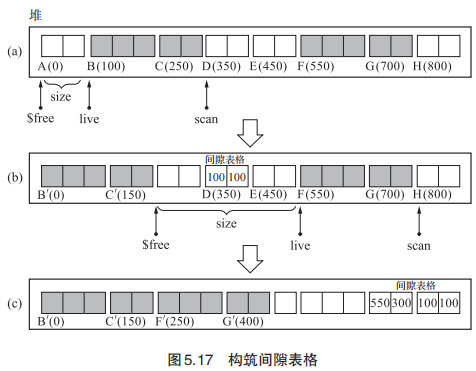
【优点】不需要forwarding 指针,因为它利用了间隙表格来存储相关的信息。但是间隙表格需要准备两个单位的空间来存放对象群信息。
【优点】因为相较于于Two-Finger算法的压缩过程保留对象顺序,所以可以利用引用对象缓存优势提高对象的访问速度。
【缺点】要维持间隙表格需要付出很高的代价,因为每次移动活动对象群都要进行表格的移动和更新。
【缺点】在更新指针时也不能忽略搜索表格所带来的消耗。在更新指针前,如果先将表格排序,则表格的搜索就能高速化。不过排序表格也需要相应的消耗,所以并不能从根本上解决问题。
ImmixGC算法
该算法比较复杂,而且也相对比较新,是Stephen M. Blackburn 和 Kathryn S. McKinley 于 2008 年研究出来的,据说论文的作者把这个算法实现到了 JikesRVM(Research Virtual Machine)A 的内存管理软件包 MMTk(Memory Management Toolkit)中。
概要
ImmixGC 把堆分为一定大小的“块”(block),再把每个块分成一定大小的“线”(line)。这个算法不是以对象为单位,而是以线为单位回收垃圾的。分配时程序首先寻找空的线,然后安排对象。没找到空的线时就执行 GC。
GC 分为以下 3 个步骤执行:(1)选定备用的 From 块。(2)搜索阶段.(3)清除阶段。
不过该算法不是每次都执行步骤 (1) 的。在 ImmixGC 中,只有在堆消耗严重的情况下,为了分配足够大小的chunk时才会执行压缩。此时会通过步骤 1 来选择作为压缩对象的备用块(备用的 From 块)。
接下来,在步骤 (2) 中从根搜索对象,根据对象存在于何种块里来分别进行标记操作或复制操作。具体来说,就是对存在于步骤 1 中选择的备用 From 块里的对象执行复制操作,对除此之外的对象进行标记操作。
步骤 (3) 则是寻找没有被标记的线,按线回收非活动对象。
以上就是 ImmixGC 的概要。
堆的构成
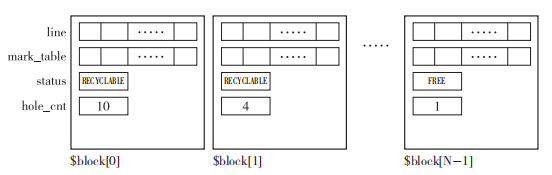
ImmixGC 中把堆分成块,把每个块又分成了更小的线。据论文中记载,块最合适的大小是 32K 字节,线最合适的大小是 128 字节。我们在此就直接引用论文中的数值。这样一来,每个块就有 32×1024÷128 = 256 个线。
各个块由以下 4 个域构成。
• line
• mark_table
• status
• hole_cnt
打个比方,用 $block[i].status 就可以访问位于第 i 号块的 status 域。
line: line 就跟它的名字一样,是每个块的线,线里会被安排对象。$block[i].line[j] 表示的就是第 i 号块的第 j 号线。
mark_table:mark_table 则是与每个线相对应的用于标记的位串。打个比方,与第 i 号块的第 j 号线相对应的用于标记的位串就是 $block[i].mark_table[j]。我们分给 mark_table[j] 一个字节,在标记或分配下面的某个常量时,将其记录在 mark_table[j] 中。
- FREE(没有对象)
- MARKED(标记完成)
- ALLOCATED(有对象)
- CONSERVATIVE(保守标记)
status:status 是用于表示每个块中的使用情况的域。我们也分给 status 一个字节,在执行GC 或分配时,记录下面的某个常量。
FREE(所有线为空)
RECYCLABLE(一部分线为空)
UNAVAILABLE(没有空的线)
初始状态下所有块都是 FREE
hole_cnt:hole_cnt 负责记录各个块的“孔”(hole)数。这里所说的孔拥有连续的大于等于 1 个的空的线。我们用这个 hole_cnt 的值作为表示碎片化严重程度的指标。如果某个chunk的hole_cnt 的值很大,它就很可能被标记为备用From空间,从而使用GC复制算法来进行处理。而hole_cnt 较小的chunk则由GC标记-清除算法进行处理。
下面的图表示了使用ImmixGC算法的堆情况:
分配过程
分配的整体过程如下图所示,核心在于判断mark_table的状态,当mark_table标记为Free才在这个line中分配内存。当然这个过程也会可能会更新chunk的hole_cnt以及status。
分配过程采取了保守标记,考虑到小型对象可能会占据 line[i+1] 的 情 况,当 mark_table[i+1] 是FREE 时,把 它 定 为 CONSERVATIVE。这 里 的 CONSERVATIVE 的 意 思 是“如 果 小 型 对 象 占 据了 line[i+1],则 mark_table[i+1] 可能会包含所分配对象的后半部分”(例如图 (a) 的$block[0].line[4] 这样的情况)。不过之后在 line[i+1] 进行分配的时候,要事先将 mark_table[i+1] 的值从 CONSERVATIVE 改写成 ALLOCATED。
这样保守的标记在标记阶段是很有用的。在标记阶段中,每次搜索对象都必须检查这个对象是否占据了其他的线,为此程序每次都要调查对象的大小,因为要调查所有活动对象,所以这项处理就带来了额外的负担。为了省去这项处理,我们才采取了较为保守的做法,即事先对小型对象打上 CONSERVATIVE这个标记。因为程序中要频繁用到小型对象,所以这个办法是非常有效的。
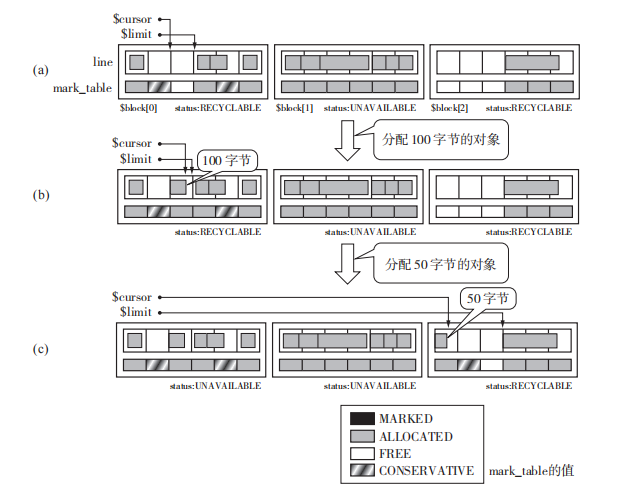
GC过程
步骤 1—选定备用From块
资料上面给的过程比较详细,需要很长时间才能理解操作的本质以及这样做的意义。经过本人的理解,将其精炼为我自己的看法。
首先统计以hole_cnt维度的FREE线以及非FREE线的总数,得到类似于下面的表。
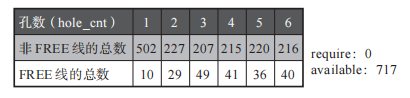
这里的require 是备用 From 块里非 FREE 线的总数,available 是除了备用 From 块以外的块所持有的 FREE 线的总数。简单来说就是评价孔数维度chunk是否释放的权重。(这里并非单个chunk最大孔数就为6孔了,而是为了举例理解该算法的思想。)
因为status 为FREE的块里面全部为FREE线,所以假设这张表有两个FREE块,此时这两个FREE块的FREE线则为256 * 2 == 512个。
此时available == 512 + 10 + 29 + 49 + 41 + 36 + 40 == 717 。我们判断require 与available 权重的方式就是直观的比大小。接下来计算出require > available 孔的数量。
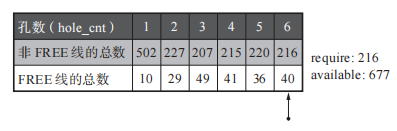
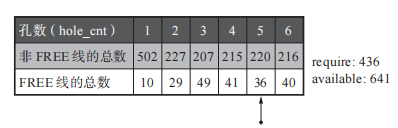
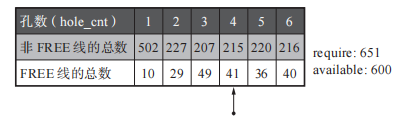
经过上面的图发现当hole_cnt为4的时候,require > available 。所以当hole_cnt > 4的所有chunk将被设置为备用FREE空间,交由GC复制算法来处理。
步骤2—搜索阶段
搜索阶段要从根开始搜索对象,根据对象分别进行标记处理或复制处理。这里的复制处理指的是将备用 From 块里的对象复制到别的块(To 块),并进行压缩。
在搜索阶段中,如果搜索到的对象在备用 From 块里,那么就会进行复制操作,如果在别的块里,就会执行标记操作。
步骤3—清除阶段
清除阶段判断mark_table[i] 的值,如果是FREE 或 ALLOCATED,则 line[i] 里就有两种情况 —没有对象或只有垃圾,因此这个线就能被回收再利用了。
当mark_table[i] 的值为 CONSERVATIVE 时,可能line[i-1] 里的对象有可能也占据了 line[i] 的空间 。如果 line[i-1] 的对象都是非活动对象,就可以将 line[i] 进行回收再利用。但是即使line[i-1] 只有一个活动对象,这个对象也有可能占据 line[i] 的空间,所以这时就不能将line[i] 进行回收再利用了。
【优点】利用线这个结构进行管理,线比块的范围小但比对象的范围大。(兼顾了效率与处理难度)
【优点】由于备用From空间的存在,碎片化严重的块可以通过GC复制算法将活动对象进行压缩。
【缺点】对象不是按顺序保存的,不能很好的利用缓存。
【缺点】由于我们曾经做过保守的标记,有些没有活动对象的线有可能无法被回收。致使堆使用效率降低。
总体来说,该算法仍然是一种比较优秀的算法。
保守式GC(Conservative GC)
定义
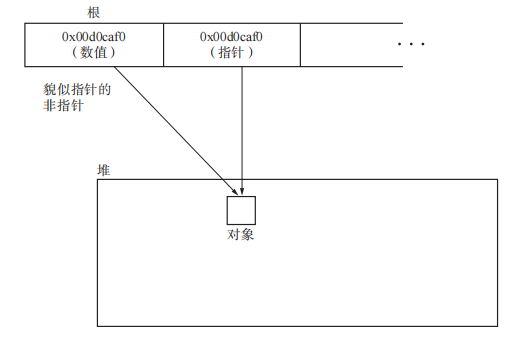
GC有两个种类,分别为“保守式 GC”和“准确式 GC”。保守式 GC指的是“不能识别指针和非指针的 GC”(因为存在不明确的根(寄存器、调用栈、全局变量空间),里面存放的可能是指针也可能是数据)。
存在貌似指针的非指针:当基于不明确的根运行 GC 时,偶尔会出现非指针和堆里的对象的地址一样的情况,这时 GC 就无法识别出这个值是非指针。如下图,这种情况很危险。在GC的时候即使这个对象真的用不到了也不会被回收,因为被错误识别成指针的数据指向了这个对象。
不明确的数据结构:类似下面的联合体,GC不能识别出这块空间是指针还是数据。
1 | union{ |
评估
优点
实现容易:编写程序设计语言的处理程序(编译器,解释器)可以花比较少的时间在GC上。
缺点
识别指针和非指针需要付出成本:需要消耗计算机资源来识别不明确的根和数据结构的值为“指针”还是“非指针”。错误识别指针会压迫堆:当识别错误时会降低堆空间利用率,不断挤压蚕食堆空间。GC算法的选择有限制:基本上不能使用 GC 复制算法等移动对象的 GC 算法。因为如果将对象移动到新空间,被错误识别成指针的数据也会被修改为新的值(此时该值为新对象的地址)。
总之缺点大于优点,建议使用准确式GC来作为GC模式。
准确式GC
准确式 GC(Exact GC)和保守式 GC 正好相反,它是能正确识别指针和非指针的 GC。创建正确的根的方法有很多种,不过这些方法有个共通点,就是需要“语言处理程序的支援”,所以正确的根的创建方法是依赖于语言处理程序的实现的。下面是几种比较常用的方法。
打标签:一个例子是在低一位打标签。v8就是这么干的。做法是把非指针(int等)向左移动 1 位(a << 1),将低 1 位置位(指针设置为1,数据不用动)。移位要注意不要让数据溢出。处理数据时先将其右移移位进行运算,等到操作完成该数据后再将其左移回去。基本上打标签和取消标签的操作都是由语言处理程序执行的。不把寄存器和栈等当作根:前提条件是创建一个正确的根,这个正确的根在处理程序里只集合了 mutator可能到达的指针,然后以它为基础来执行 GC。Example,当语言处理程序采用 VM(虚拟机)这种构造时,有时会将 VM 里的调用栈和寄存器当作正确的根来使用。
【优点】保守式GC的缺点在这里都得到了解决。
【缺点】同样保守式的优点也是它的缺点,也就是实现困难。
【缺点】打标签的方式可能会影响程序整体的运行速度。
优化措施
间接引用
解决的是GC算法的选择有限制的问题,使用该技术就可以使用GC复制算法了。间接引用实际上就是加了一个中间层。由于加了一个中间层,当对象移动时,中间层的值进行了修改,而根始终指向中间层,根的值并没有做任何更改。
【优点】可以使用类似于GC复制算法等移动对象的算法了,可选择性多了。
【缺点】因为必须将所有对象都(经由句柄)间接引用,所以会拉低访问对象内数据的速度,这会关系到整个语言处理程序的速度。
MostlyCopyingGC
概念
这是1989 年 诞生的一个保守式 GC 复制算法。这个算法能在不明确的根的环境中运行 GC 复制算法。堆被分成若干个一定大小的页。页有三种形式。如下图:
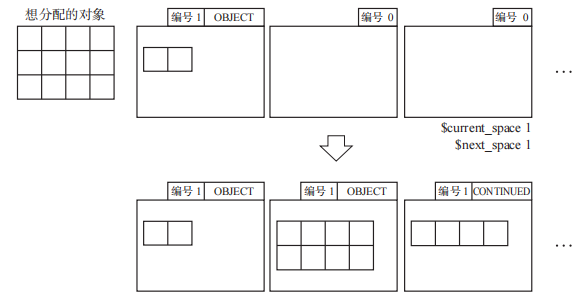
OBJECT表示正在使用的页,CONTINUED表示当正在使用的页跨页时将被设置在第2个页之后,没有标志的表示空白页。
默认一个新的堆中全部是空白页,申请小对象基本只会分配在已有的OBJECT页或者新建的OBJECT页;而申请大对象基本会新建OBJECT页和CONTINUED页。
分配过程
如果正在使用的页里有符合 mutator 申请的对象大小的chunk,对象就会被分配到这个页。
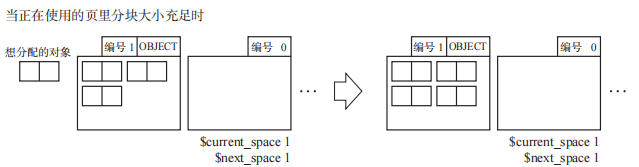
如果当正在使用的页里没有大小充足的chunk时,对象就会被分配到空的页,然后正在使用的这个新页会被设置 OBJECT 标志。
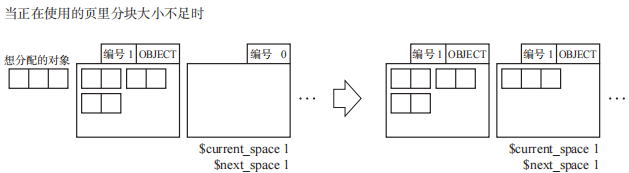
当 mutator 要求大对象时,分配程序会将对象跨多个页来分配。在跨多个页分配时,和平时的分配一样,也会在开头的页设定OBJECT,然后在第 2 个页之后设置 CONTINUED 标志。
GC过程
初始状态,这里的$current_space是From页的编号,$next_space是To页的编号,此时二者相同。
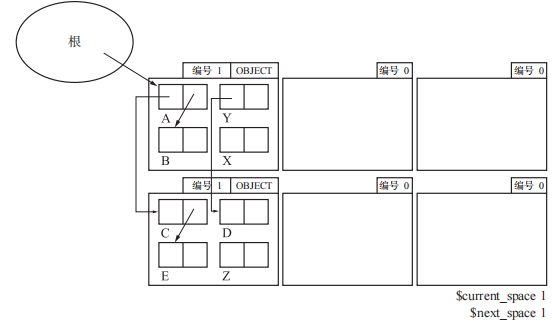
将从根引用的对象的页“晋升”(promotion)到 To 页,此时$next_space发生了改变,目的是为了区分标记From页和To页。
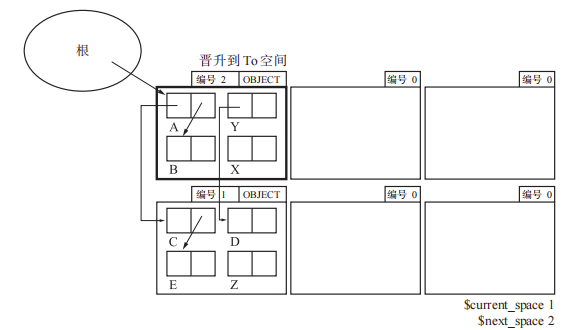
接着还是按照由根到堆的顺序将From页的活动对象复制到To页。
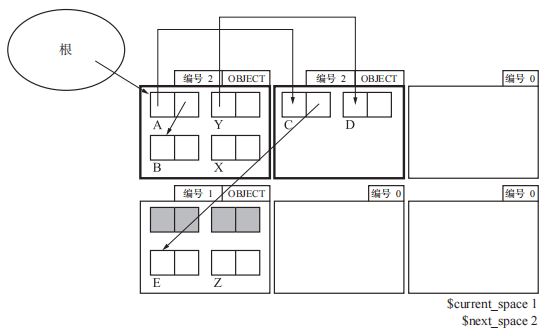
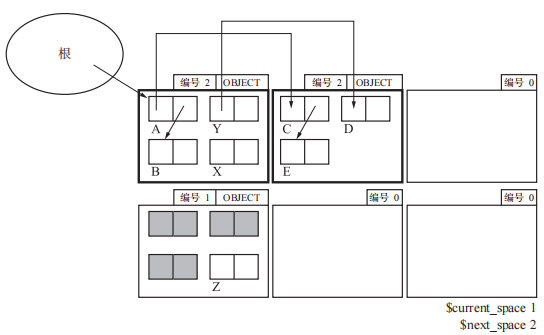
将 To 页里的所有子对象复制完毕后,GC 就结束了。这时程序会将 $current_space 的值设定为 $next_space 的值。
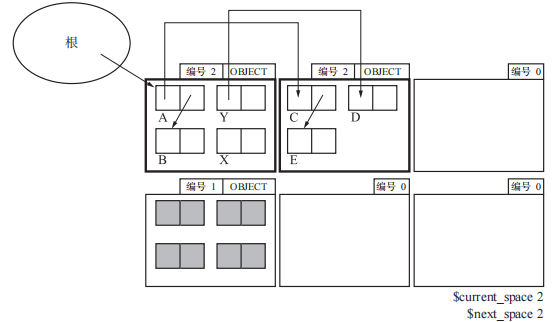
不过此时垃圾对象 X、Y、D 都没有被回收(因为Y不能被任何指针索引到,而D由Y索引,所以二者都是垃圾对象)。实际上这就是 MostlyCopyingGC的特殊之处。它不会回收包含有从根指向的对象(图中的 A)的页里的垃圾对象,而且也不会回收这个垃圾对象所引用的对象群。举个极端的例子,如果所有的页里都有从根引用的对象,那么所有的垃圾都不能被回收。
这个缺点可以通过调整页大小得到改善。如果缩小页,那么即使页里的对象是从根引用的,我们也能把损失降到最低。不过如果页太小了,就会增加页总数,增大分配和 GC 所需要的成本。所以将页调整到合适大小是非常关键的。据文献 [17] 记载,有试验结果表明页的合适大小在 512 字节。
【优点】能在保守式 GC 里使用 GC 复制算法。兼顾了保守式GC(实现简单)和GC复制算法的优点。
【缺点】也同样由GC复制算法的缺点,还有一个特有缺点是在包含有从根引用的对象的页内,所有的对象都会被看成活动对象。也就是说,垃圾对象也会被看成活动对象,这样一来就拉低了内存的使用效率。
黑名单
处理的是错误识别指针会压迫堆的问题,通过黑名单标记可能存在问题的内存,减小其带来的危害(但不能消除)。
在指针的错误识别中,当被错误判断为活动对象的那些垃圾对象的大小过大以及子对象过多时,造成的危害会相对来说比较大。而当其垃圾对象的大小比较小而且该对象没有子对象时,造成的危害会比较小。
基于这一点,黑名单就是一种创建“需要注意的地址的名单”的方法。这个黑名单里记录的是“不明确的根内的非指针,其指向的是有可能被分配对象的地址”。我们将这项记录操作称为“记入黑名单”。黑名单里记录的是“需要注意的地址”。一旦分配程序把对象分配到这些需要注意的地址中,这个对象就很可能被非指针值所引用。也就是说,即使分配后对象成了垃圾,也很有可能被错误识别成“它还活着”。所以我们在黑名单中的内存可以分配上述提到的大小比较小且没有子对象的对象,这样为如果这样的对象成了垃圾,即使被错误识别了,也不会有什么大的损失。说白了就是风险最小化。
【优点】可以缓解错误识别指针会压迫堆的问题。堆的使用效率页得到了提升。
【缺点】分配对象时需要检查黑名单,需要花费一定的时间。
无法判断该技术是否好用,具体是否应用该技术取决于工程实际测试时表现的性能。
分代垃圾回收(Generational GC)
定义
分代垃圾回收中把对象分类成几代,针对不同的代使用不同的 GC 算法,我们把刚生成的对象称为新生代对象,到达一定年龄的对象则称为老年代对象。我们将对新对象执行的 GC 称为新生代 GC(minor GC)。将面向老年代对象的 GC 称为老年代 GC(major GC)。
分代垃圾回收,基于的是“大部分的对象,在生成后马上就会变成垃圾”这一经验上的事实为设计出发点。
实现
这里介绍下Ungar的分代垃圾回收,它是由 David Ungar 研究出来的把 GC 复制算法和分代垃圾回收这两者组合运用的方法。
堆结构如下。两个幸存空间可以分成From幸存空间和To幸存空间,生成空间和From幸存空间都会使用类似于GC复制算法将活动对象拷贝到To空间,之后进行From幸存空间和To幸存空间的swap。可能会出现To幸存空间可能不能承载所有活动对象的任务(这种情况可能比较少,因为新生代对象的定义就是生命比较短的对象),这时就会临时将老年代空间当作承载容器。只有达到一定年龄的对象才会被移动到老年代空间中。老年代空间满了之后会执行GC标记-清除算法。这时可能会出现老年代对象指向新生代对象的情况。
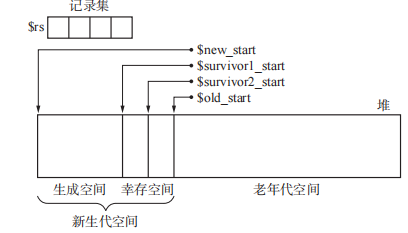
对于新生代对象的索引有三种情况:根索引、新生代对象索引、老年代对象索引。分代垃圾回收的优点是只将垃圾回收的重点放在新生代对象身上,以此来缩减 GC 所需要的时间。不过考虑到从老年代对象的引用,结果还是要搜索老年代堆中的所有对象,这样一来就大大削减了分代垃圾回收的优势。这时我们可以维护一个列表来维护从老年代指向新生代的对象,这个列表就叫做记录集。写入记录集之前会判断该对象是否在老年代且指向的对象是否在新生代,该对象是否没有保存在记录集中(通过标志位remembered来判断),如果都满足条件则将该对象的索引写入记录集中。
1 | // write_barrier:写入记录集。 |
对象头包含了很多东西,有常规的对象的种类和大小,还有
- 对象的年龄(age):只在新生代对象头,如果年龄到达阈值则进入老年代。
- 对象是否已经被复制过(forwarded):只在新生代对象头,防止复制相同对象。
- 是否被记录集记录(remembered):只再老年代对象头,防止重复再记录集记录。
对象还有个forwarding指针,obj.forwarding,指向了要复制的空间。
1 | // new_obj:主要逻辑就是复制内存,移动指针。和GC复制算法很像。 |
评估
优点
提高了吞吐量:基于“很多对象年纪轻轻就会死”的理论。通过分代的方式快速处理了大部分对象,而难以变为垃圾的老年代对象也没有必要频繁的进行GC访问。
缺点
可能起反作用:虽然“很多对象年纪轻轻就会死”毕竟只适合大部分那情况,并不适用于所有程序。当那少部分的程序使用分代的方式处理时不仅新生代GC花费的时间会增多,老年代的GC也会频繁运行,写入记录集的操作也会降低吞吐量。最大暂停时间问题:老年代使用了GC标记-清除算法,对于最大暂停时间有影响。跨代的循环引用无法一次性回收:只有等新生代的对象年龄到了放在老年代才能得到处理。记录集比较占用空间:每有一个老年代指向新生代的对象,就会占用一个字存放在记录集中。
优化措施
记录各代之间的引用的方法
解决的是记录集比较占用空间的问题,可以通过两种方式。
一是将老年代内存分为一节节的小内存,每节小内存如果有对象指向新生代空间,那么该节的标志位置为1 。但是当老年代对象比较多的时候,搜索每节内存都要花费大量时间。
二是通过操作系统的页面管理程序,很多操作系统都是以页面为单位来管理内存空间的。因此如果在卡片标记中将卡片和页面设置为同样大小,我们就能得到 OS 的帮助。实际上利用的也是第一点提到的思路,只不过有操作系统协助管理。但是这个方法只适用于能利用页面重写标志位或能利用内存保护功能的环境。而且不只搜索老年代到新生代会进行索引,老年代对老年代进行索引操作系统也会进行标记。
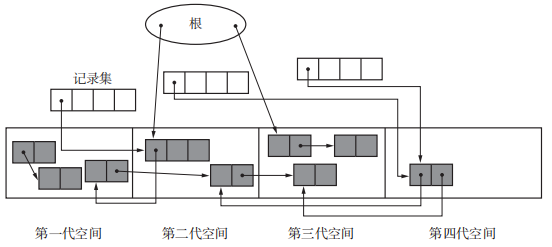
多代垃圾回收
它是为了解决最大暂停时间问题。分代垃圾回收将对象分为新生代和老年代,通过尽量减少从新生代晋升到老年代的对象,来减少在老年代对象上消耗的垃圾回收的时间。
但是如果代数太多,各代之间的引用就会变得更复杂,每代的空间也就越小,各代GC花费的时间也越长了。
Train GC
该方法是为了解决跨代的循环引用无法一次性回收和最大暂停时间问题。
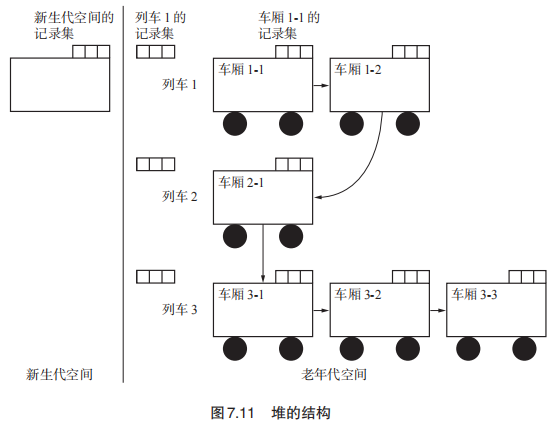
Train GC的特点有
- 引入了“列车”与“车厢”的概念,GC的对象是第一个列车的第一个车厢。
- 新生代对象不在分为生成空间、2 个大小相等的幸存空间这三块空间了,而是仅仅只有一块新生代空间,毕竟To空间放在老年代空间里面了。
- 记录集有多个,并且是单向的(因为GC的对象仅仅在第一个列车里面)。新生代、列车、车厢都有记录集。
新生代GC将被引用的新生代对象复制到引用它的老年代对象的车厢中,并把根引用的新生代对象放入新的车厢中
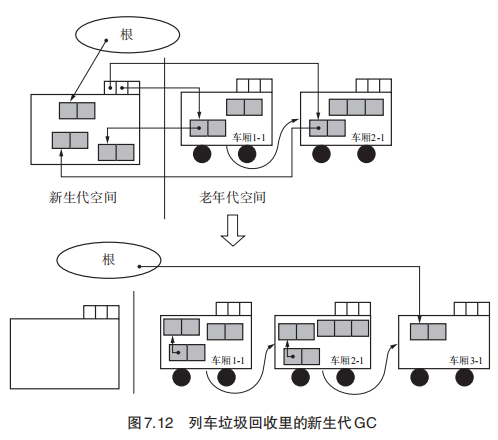
1 | // copy:将新生代对象复制到老年代的车厢中。 |
而正常的老年代GC流程则是按照搜索第一个列车->第一节车厢的顺序清空第一个车厢的活动对象并进行垃圾回收。先把列车一被其他列车引用的对象复制到其他列车中,如图7.14。之后再将1.1车厢被列车一其他车厢引用的对象复制出去,这样车厢一的活动对象就已经被清空了。
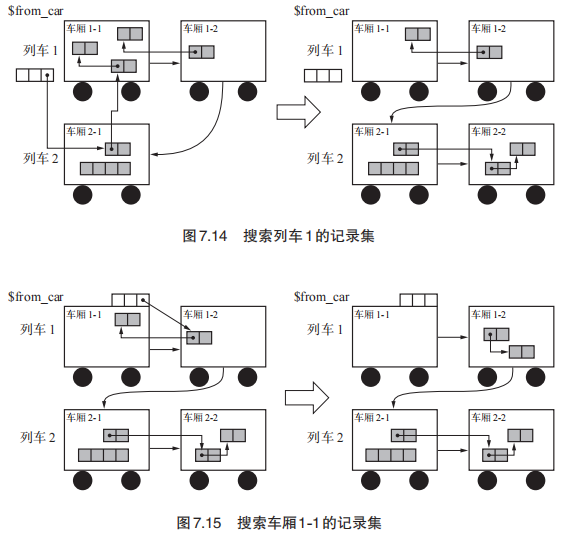
而当列车一没有其他列车引用其中的对象时,可以将列车一这个列车一并回收。
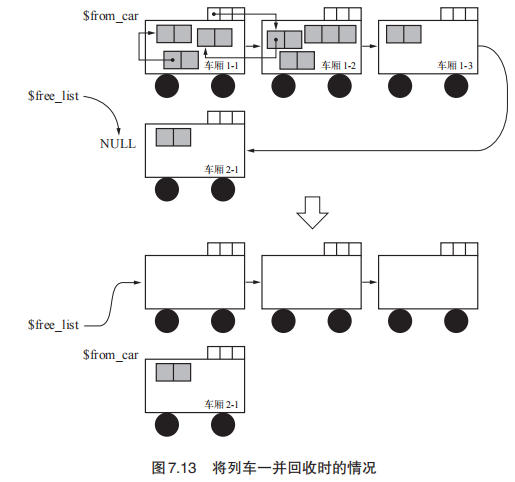
【优点】可以减少最大暂停时间,因为每次进行GC的只是一节车厢,只占堆中比较小的一部分。
【优点】可以回收循环垃圾,毕竟通过列车的记录集就可以知道这个列车是不是孤儿,如果是则将整个列车回收。
【缺点】因为记录集变多了,所以吞吐量更低了,占用的空间也相应的增加。
【缺点】如果对象大小大于一个车厢,该算法就不能对他进行处理,需要安排到新生代和老年代以外的堆进行回收。
增量式垃圾回收(Incremental GC)
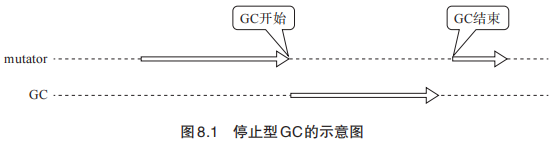
定义
如果当GC执行的时间过长导致这段时间mutator完全不能工作,那么就将这种GC叫做停止型GC。根据mutator的用途不同,有时候停止型GC是非常要命的。因此我们可以采用慢慢发生变化的方式进行GC,这种方式叫做增量式垃圾回收。停止型GC和增量式垃圾回收图如下。
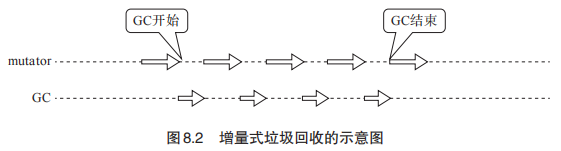
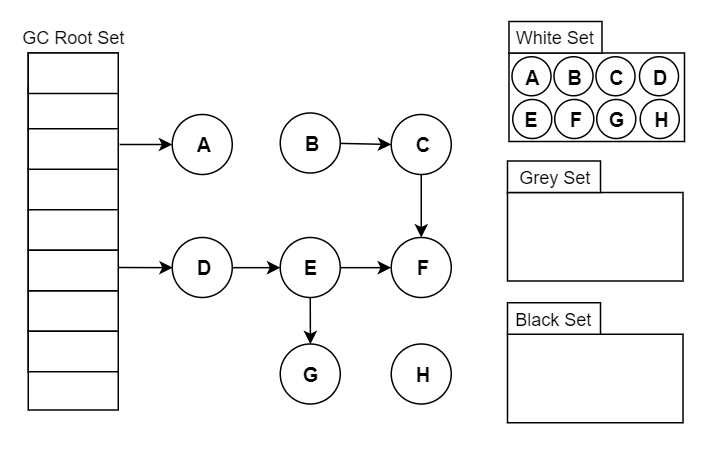
描述增量式垃圾回收的算法可以方便的使用三色标记算法(Tri-color marking)。
- 白色:还未搜索过的对象
- 灰色:正在搜索的对象
- 黑色:搜索完成的对象
以 GC 标记 - 清除算法为例:
根查找阶段:GC 开始运行前所有的对象都是白色。GC 一开始运行,所有从根直接到达的对象都会被放到栈里并被标记为灰色。标记阶段:灰色对象会被依次从栈中取出,其子对象也会被涂成灰色。当其所有的子对象都被涂成灰色时,对象就会被涂成黑色。清除阶段:当 GC 结束时已经不存在灰色对象了,活动对象全部为黑色,垃圾则为白色。这时将白色对象全部回收。
三色标记算法这个概念不仅能应用于 GC标记 - 清除算法,还能应用于其他所有搜索型 GC 算法。这里面有个数据结构存放要遍历标记的对象叫做标记栈,标记栈里面存放的一定是灰色对象,代表里面的对象需要进行处理。而从标记栈中出来的对象则会被涂成黑色,代表处理完毕并且它是个活动对象。
实现
1 | // incremental_gc:增量式垃圾回收。分为三个阶段——根查找阶段、标记阶段、清除阶段。 |
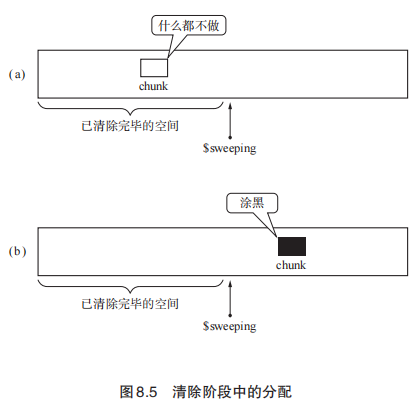
标记遗漏
当进程由GC的标记阶段切换到mutator运行时,如果执行了这样一段代码
1 | var C = objB.fieldC; |
此时由B->C的引用转到了A->C的引用上。而A已经被涂黑,也就是说他不在标记栈中了,也就不会处理A了。此时如果又从mutator运行状态切换到GC的标记阶段时,本来应该继续通过mark(B)给C打上标记,但是此时C是由A索引的了。C就成孤儿了,如果C本身是个活动对象,那么由于无法对C进行涂色导致可能会释放活动对象的状况,从而导致程序异常。
写入屏障
如果新引用的对象 newobj 是白色对象,就把它涂成灰色。(迪杰斯特拉的写入屏障)
1 | // write_barrier:这里的mark可能表示灰色或者黑色,区分灰和黑的方式就是它是否在标记栈中,在标记栈中说明它没有被处理也就是灰色,而不在标记栈中说明已经被处理完了所以是黑色。 |
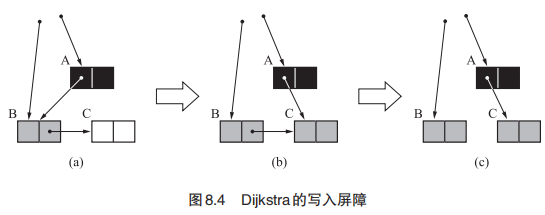
评估
优点
缩短最大暂停时间: GC 与 mutator 交替运行,因此不会长时间妨碍 mutator 运行。
缺点
降低了吞吐量:用到了写入屏障,增大了处理的额外负担。
其他实现方式
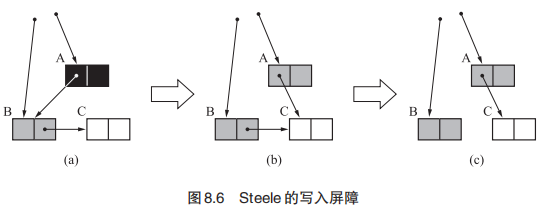
Steele的算法
由Steele 1975年开发的算法。这个算法和上面有一点区别,这里obj.mark为True就代表它为黑色,而标记为False则代表它为灰色或者白色。区分灰色和白色的方式和上面相同,就是判断对象是否在标记栈中。
1 | // mark:与上面mark的区别是灰色的obj.mark值也是FALSE,而上面的obj.mark值为True。 |
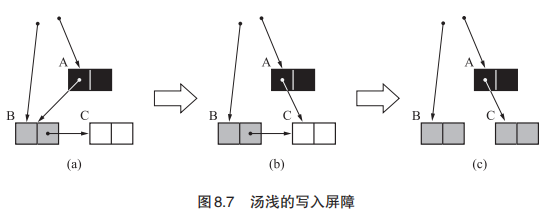
汤浅太一的算法(Snapshot GC)
1990 年汤浅太一开发,也称为“快照 GC”(Snapshot GC)。核心在于它会处理B->C的指针,即使A->C黑色对象指向白色对象也没有关系。在B->C置为null时会触发写屏障, 这时会判断C是否为白色,如果为白色将其涂灰。
写入屏障实现方式
1 | // write_barrier:这个写入屏障和刚刚两个不同的地方在于它发生在取消指针的阶段(也就是B->C的阶段),前两个都是在转移指针的阶段(也就是从A->C的阶段) |
三种方式的比较
| 提出者 | A | B | C | 时机 | 动作 |
|---|---|---|---|---|---|
| Dijkstra | - | - | 白 | A->B | 将C涂灰 |
| Steele | 黑 | - | 白或者黑 | A->B | 将A恢复成黑色 |
| 汤浅 | - | 白 | - | B->C | 将C涂灰 |
这样看来,它们 3 个各不相同。实际上不仅是写入屏障,在分配等方面也存在着差异,所以我们没法简单地进行比较。不过即使存在着这么大的差异,各种写入屏障也都能顺畅运行。
RC Immix算法
定义
传统的引用计数法有一大缺点,吞吐量过低。本次介绍的两种方式都会改善其吞吐量到可以实际应用的级别,但是其最大暂停时间可能会有相应的增长,毕竟没有一种算法是完美的。
合并型引用计数法
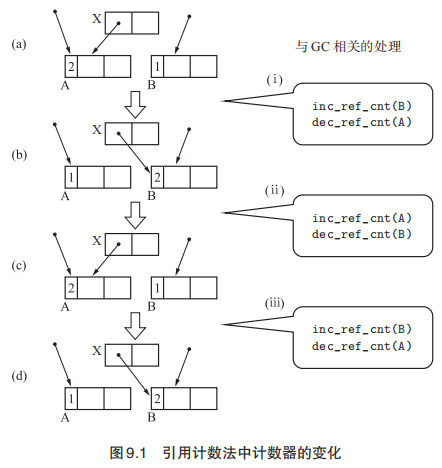
合并型引用计数法是 2001 年由 Yossi Levanoni 和 Erez Petrank 开发的算法。常规的引用计数法步骤可能会造成计数器的频繁修改,造成很大的系统开销,如下所示
引用计数法在之前介绍过一个可以提高系统吞吐量的方式,叫做延迟引用计数法。从根引用的指针的变化不反映在计数器上。通过维护一个ZST表,即使频繁重写对象的引用关系也会降低系统开销。
不过在延迟引用计数法之上还可以进行优化。考虑到图9.1的情况,通过多次变化,(a)->(b)->(c)的变化被抵消掉了。如果我们把注意力放在某一时期最初和最后的状态上,在此期间不进行计数器的增减,这样就可以减少很多无效的计算。这种方式就叫做合并型引用计数法。将指针的改动信息注册到更改缓冲区(Modified Buffer)。大致的过程如下图,(e)步骤实际上A的引用计数经过处理后应该变为1,而B则变为2 。
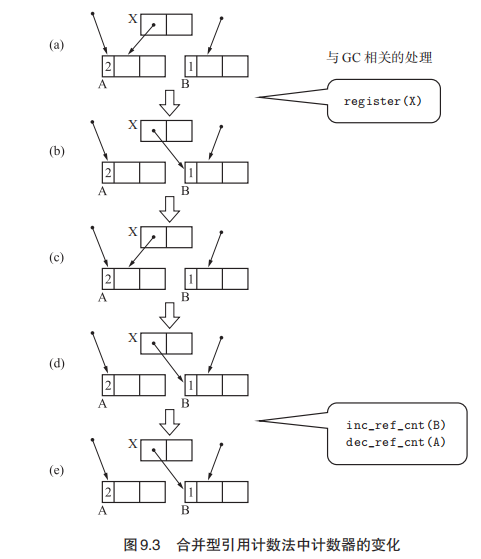
我们将指针改动了的 X 和指针改动前被 X 引用的 A 注册到了更改缓冲区。结束时X指向了B。之后对B的计数器加一,对A的计数器减一。
1 | // garbage_collect:先进行加法再进行减法的目的是和之前一样,为了确保A和B是同一对象的情况也能顺利运行。 |
【优点】增加了吞吐量。它不是逐次进行计数器的增减处理,而是在某种程度上一并执行,所以能无视增量和减量相抵消的部分。
【缺点】是增加了 mutator 的暂停时间,这是因为在查找更改缓冲区的过程中需要让mutator 暂停。当然,如果更改缓冲区的大小比较小,就能相应缩短暂停时间,不过这种情况下就没法指望增加吞吐量。这方面需要我们加以权衡好好调整。
RC Immix(合并型引用计数法和Immix的融合)
在以往的合并型引用计数法中,通过查找更改缓冲区,计数器值为 0 的对象会被连接到空闲链表,为之后的分配做准备。这和单纯的引用计数法是一样的。
Immix 中不是以对象为单位,而是以线为单位进行内存管理的,因此不使用空闲链表。如果线内一个活动对象都没有了,就回收整个线。只要线内还有一个活动对象,这个线就无法作为chunk回收。RC Immix 中不仅对象有计数器,线也有计数器,这样就可以获悉线内是否存在活动对象。不过线的计数器和对象的计数器略有不同。对象的计数器表示的是指向这个对象的引用的数量,而线的计数器表示的是这个线里存在的活动对象的数量。如果这个数变成了 0,就要将线整个回收。下图表示的是线的计数器。
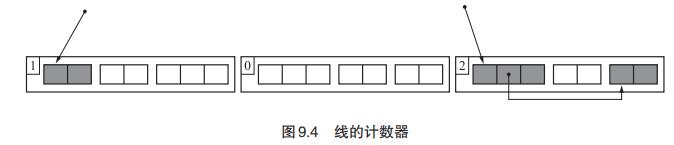
为了减少额外负担,线的计数器里记录的不是“指向线内对象的引用的数量”,而是“线内活动对象的数量”。对象生成和废弃的频率要低于对象间引用关系变化的频率,这样一来更新计数器所产生的额外负担就小了。
1 | // 这里的线包含了所有活动对象,当某个对象的计数器减为0时,线的计数器减一(因为线包含的是活动对象的数量);当线的计数器减为0时回收整个线。 |
但是这样处理可能会有内存碎片,RC Immix算法提供了两种方式进行压缩。
被动碎片整理(Reactive Defragmentation):RC Immix 和合并型引用计数法一样,在更改缓冲区满了的时候都会查找更改缓冲区,这时如果发现了新对象,就会把它复制到别的空间去。这里使用的是Cheney的GC复制算法(遍历的方式进行GC复制算法)。简单来说:更改缓冲区里存放的都是新对象(没有经历过 GC 的对象称为新对象,新对象是在上一次 GC 之后生成的。因此指向新对象的所有指针也是在上一次 GC 之后生成的。更改缓冲区里记录的是从上一次 GC 开始到现在为止指针改动过的对象。所有指向新对象的指针都是在上一次 GC 之后生成的。也就是说,所有引用新对象的对象都被注册到了更改缓冲区。),RC Immix 中以新对象为对象进行压缩。不过被动的碎片整理只会对活动对象中的新对象进行压缩。这样随着程序的逐步运行,旧对象可能会导致碎片化。此外,因为我们是以引用计数法为基础的,所以不能回收循环垃圾。为了解决如上问题,在 RC Immix 里还要进行一项压缩,那就是积极的碎片整理。
积极的碎片整理(Proactive Defragmentation):上面说被动的碎片整理有两个缺点。一是无法对旧对象进行压缩,二是无法回收有循环引用的垃圾。通过GC标记-压缩算法可以有效的解决这个问题。不过这个碎片整理应该被当作辅助碎片整理来用,毕竟这会增大最大暂停时间。当chunk的总大小下降到一定值(例如全体堆的 10%)时再执行它为好。
【优点】吞吐量提高的比较明显。据论文记载,与以往的引用计数法相比,其吞吐量平均提升了 12%。根据基准测试程序的情况,甚至会超过搜索型 GC。吞吐量得到改善的原因有两个。其一是导入了合并型引用计数法。因为没有通过写入屏障来执行计数器的增减操作,所以即使对象间的引用关系频繁发生变化,吞吐量也不会下降太多。另一个原因是撤除了空闲链表。通过以线为单位来管理chunk,只要在线内移动指针就可以进行分配了。此外,这里还省去了把chunk重新连接到空闲链表的处理。
【缺点】RC Immix 和合并型引用计数法一样,都会增加暂停时间。不过如前所述,可以通过调整更改缓冲区的大小来缩短暂停时间。另一个缺点是“只要线内还有一个非垃圾对象,就无法将其回收”。在线的计数器是 1,也就是说线内还有一个活动对象的情况下,会白白消耗大部分线。
总结
有过C或C++开发经验的童靴都知道,C/C++的动态内存(一般是堆内存)是通过malloc等函数手动申请,并交由Free等函数手动释放的,这就需要我们对我们申请的每一块内存负责。如果无限申请资源而不去使用并释放,那么堆内存将会被分配至耗尽浪费系统资源并产生性能问题。如果释放的时候并没有回收空间或者回收多次,或者指向空间的指针没有被置空,那么就可能会出现安全漏洞。
GC提供了这样一种机制,开发者无需关注这种动态内存的释放问题,具体的实现是通过程序设计语言处理引擎(比如v8)来管理无用对象的垃圾回收,从而大大减少了出bug或者安全漏洞的几率。
主流的GC算法分为两类,分别是搜索型算法和引用计数法,GC标记-清除算法与GC复制算法等等都需要搜索根,所以他们都属于搜索型算法。而引用计数法独树一帜,当计数为0时可以直接将其清除掉。
实现篇
v8
v8官方博客
free-garbage-collection
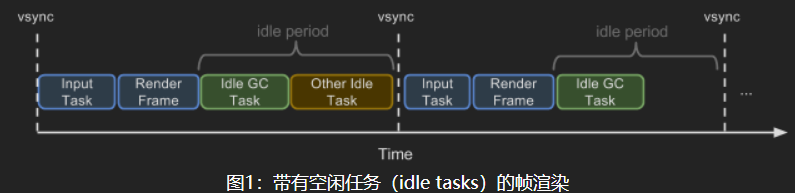
发布时间 2015-08-07
这里翻译有一些错误,应该翻译为空闲时垃圾回收,作者举的例子为在播放60 帧动画时仍存在idle period,可以利用这段空闲时间进行垃圾回收。
这里使用的垃圾回收思想为分代垃圾回收,新生代使用GC复制算法,而老年代为GC标记-清除算法,不压缩的好处是可以节省一些压缩的时间,坏处还是内存碎片化,分配空间困难等问题。
jank-busters
发布时间 2015-10-30
实际上是对最大暂停时间的避免,主要采用了下面几种方式
- 之前在分配大量ArrayBuffer 的场景下(例如基于WebGL的应用,WebGL是一个基于JS的3D绘图协议)对这些缓冲区的GC会使最大暂停时间不可避免的变长。此时采取的方式是在每次使用ArrayBuffer 时进行检查来判断是否使用,如果未使用则将其空间释放,这样是将统一处理折衷成了分散处理,每次使用缓冲区都要进行检查可能会影响性能。
- 众所周知v8与BLINK有各自的堆空间存放活动对象,当BLINK使用v8对象时,v8需要维护一个状态表去表示那些BLINK区引用的对象,使v8在GC时不去回收这些对象。还是像之前的场景一样,对于WebGL这种会产生大量缓冲区的协议,就需要维护大量这样的全局引用来管理其生命周期。幸运的是,传递给 WebGL 的对象通常只是传递而从未真正修改过,从而可以进行简单的逃逸分析。使用小数组作为参数的 WebGL 函数,可将这个参数数据复制到栈上,减缓GC压力。
- 通过并发线程共同处理GC过程。主要清理老年代(新生代的GC复制算法效率很高最大暂停时间很短)。
jank-busters-two:orinoco
发布时间 2016-04-12
v8团队新命名了代号为Orinoco 的垃圾回收器,Orinoco 基于这样的想法,即在没有严格的分代边界的情况下实现大部分并行和并发的垃圾回收器将减少垃圾回收的 jank 和内存消耗,同时提供高吞吐量。此次的博客主要的性能提升体现在以下三个方面。
- 新生代的晋升与老年代的压缩之间没有依赖关系,因此 Orinoco 可以并行执行这些阶段。
- GC复制算法以及压缩过程等都涉及到对象的移动,对象移动的过程中需要更新指向该对象的指针。之前的做法是新生代和每个老年代都维护一个指向该区域的指针列表,但是这样可能会有重复条目的指针,这样多线程操作的时候可能会导致数据争用。改进的方式是对堆空间维护一个标志位区域。指向其他空间的指针位置在其标志位对应处置1,代表该位置有指向其他区域的指针。
- 将老年代中分配的所有对象涂黑,这样GC的整个过程都不会操作他们。因为老年代的含义就是比较稳定的对象,所以这个逻辑并没有什么问题。而最终在合适的时机进行老年代对象的垃圾回收。
Orinoco:新生代垃圾回收
发布时间 2017-11-29
新生代的垃圾回收方式一般为GC复制算法,但是在多线程环境中对GC复制算法的实现是一个问题。
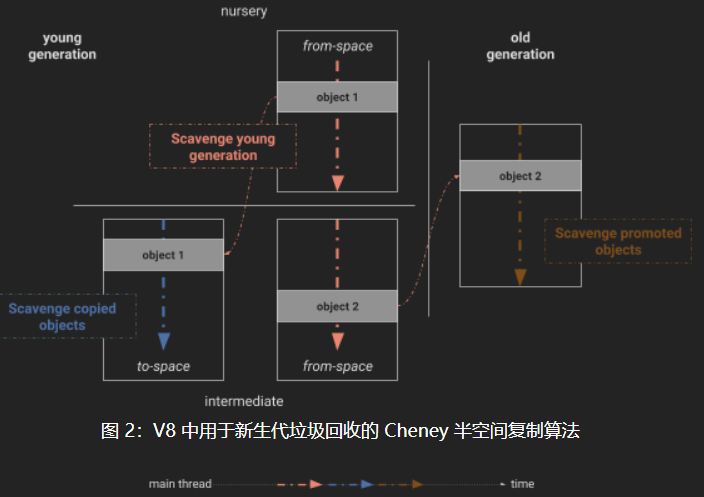
V8 将其托管堆(managed heap)分成几代,其中对象最初在新生代(young generation)的“区域(nursery)”中分配。在垃圾回收中幸存下来后,对象被复制到中间代(intermediate generation),它仍然是新生代的一部分。在另一次垃圾回收中幸存下来后,这些对象被移动到老年代(old generation)(见图 1)。
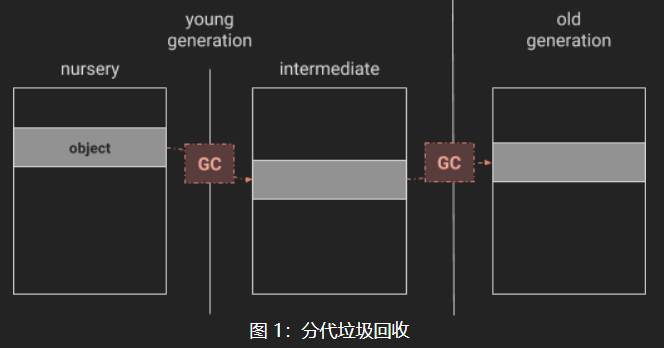
文章中介绍了三种新生代使用的GC复制算法
- 单线程的GC复制算法。在v6.2之前v8使用的是Cheney的GC复制算法。也就是利用迭代方式实现的。基本和算法篇的描述一致。单线程Cheney算法最初设计时考虑到了最优的单核性能。但从那时起,时代变了。即使在低端的移动设备上,CPU内核也是有很大提升。更重要的是,这些内核通常都是正常运行的。为了充分利用这些内核,V8垃圾收集器必须进行现代化改造。
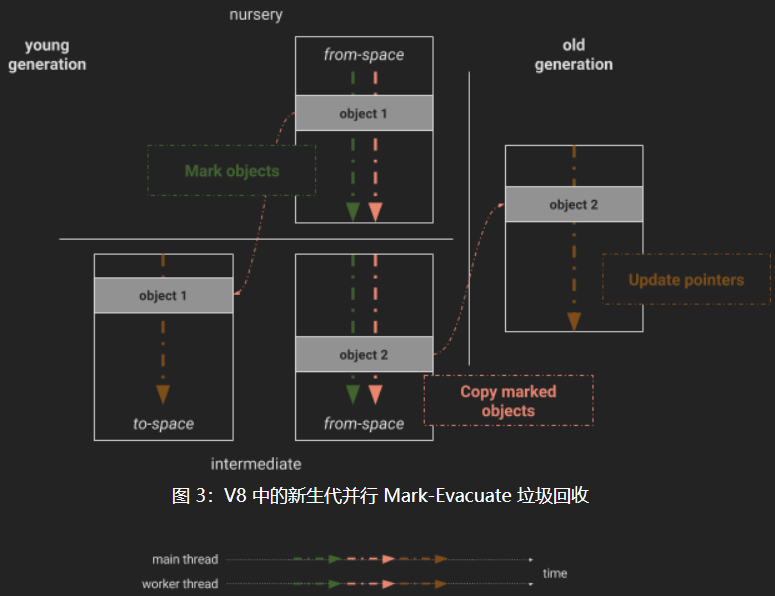
- 并行 Mark-Evacuate。多个线程同时进行新生代对象的复制,这时就需要将对象进行标记,复制完成后将对象取消标记,此时不可避免地to空间会碎片化,这时最后进行压缩的操作。并行标记最大优点是可以确切标记的活动对象。可以通过移动和重链接包含活动对象的页面来避免复制,这些活动对象也是由完整的Mark-Sweep-Compact收集器执行的。然而,在实践中,这在综合基准测试中很常见,很少出现在真正的网站上。并行并行标记的缺点是执行三个单独的锁步阶段的开销。当在堆上调用垃圾收集器时,这种开销尤其明显,堆上的对象大多是死对象,这是许多实际web页面的情况。
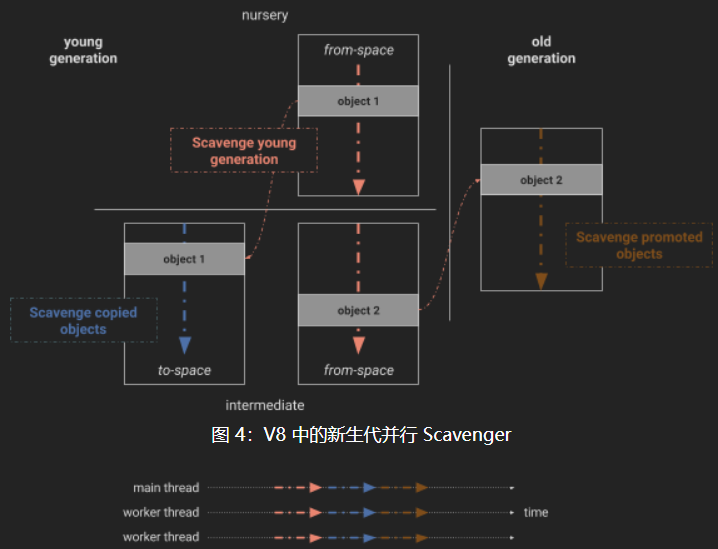
- 并行Scavenger将标记-复制-修改指针过程变为原子过程,V8使用多线程和负载平衡机制来扫描Root(增量回收)。
Tracing from JS to the DOM and back again
发布时间 2018-03-01
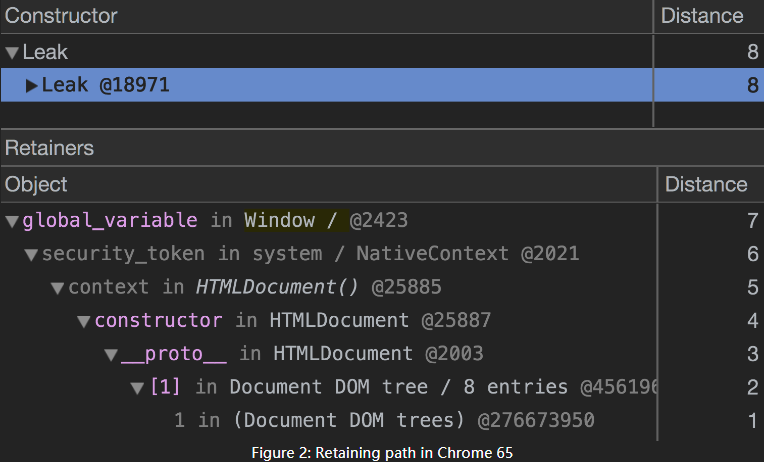
功能:Chrome 66以后的版本可以在DevTools中追踪跨v8对象与DOM对象的访问。
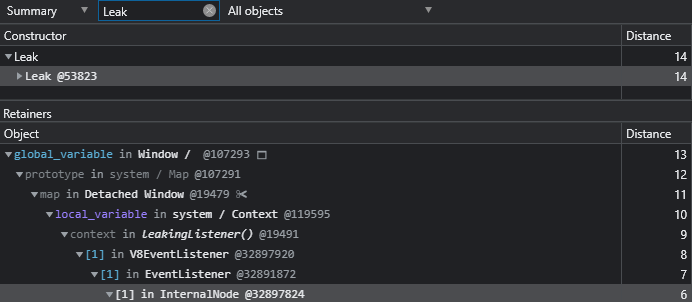
背景:当由于忘记释放无意申请的空间时将会发生内存泄露,原始的DevTools无法跨DOM追踪到js代码,新增的该功能可以更精确的定位到发生泄露的具体对象或函数。
此时只第一行精准定位到了global_cariable
此时追踪到了v8的EventListener函数
并发标记
发布时间 2018-06-11
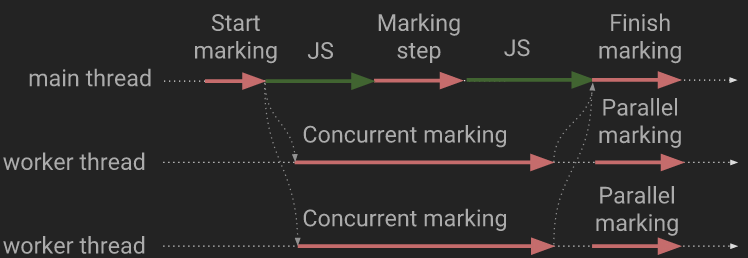
为了减少stop-the-world的问题采用了增量垃圾回收(三色标记法),V8 使用 Dijkstra 风格的写屏障(write-barrier)机制来解决标记遗漏的问题,但我们也说过,加入写屏障势必降低应用程序的吞吐量,所以可以通过增加线程的方式来处理这个问题,主要方式为并行和并发。

然而最终,主线程通过扫描 root 并填充标记工作表来启动标记。之后,它会在工作线程中发布并发标记任务。工作线程通过合作排除标记工作表来帮助主线程加快标记进度。偶尔主线程通过处理 bailout worklist 和标记工作表来参与标记。标记工作表变空之后,主线程完成垃圾收集。在最终确定期,主线程重新扫描 root,可能会发现更多的白色对象。这些对象在工作线程的帮助下被并行标记。
2019年更新的Orinoco讨论
发布时间 2019-01-03
相当于对之前提到的技术进行总结。
v8宏观上采用了分代垃圾回收的技术。基于的理论是代际假说(The Generational Hypothesis);代际假说表明很多对象在刚刚分配后随即就释放掉了。新生代使用了前面提到的并行Scavenger技术,核心是GC复制算法。老年代使用了GC标记-清除算法。至于整理,v8采用了一种叫做碎片启发式(fragmentation heuristic)的算法来整理内存页。由于分配内存空间给很多常驻内存( long-living)的对象时,复制这些对象会带来很高的成本。所以v8只选择整理碎片化比较严重的内存页,并且对其他内存页只进行清除而不是也同样复制活动对象。
v8中采用了并行垃圾回收、并发垃圾回收、增量式垃圾回收、空闲时回收等方式大大提升了v8的性能。前面也都提到过相关的技术。
Scavenger 回收器将新生代的垃圾回收时间减少了大约 20% - 50%,空闲时垃圾回收器在 Gmail 网页应用空闲的时候将 JavaScript 堆内存减少了 45%。并发标记清理可以减少大型 WebGL 游戏的主线程暂停时间,最多可以减少 50%。
最后提到了BLINK本身也是有一个垃圾收集器叫做Olipan,此时Orinoco尚未与其进行联动。
high-performance-cpp-gc
发布时间 2020-05-26
启用Oilpan项目的目的是为了用于管理 C++ 内存(因为BLINK引擎对象使用C++实现),该内存可以使用跨组件跟踪连接到 V8,该组件将耦合的 C++/JavaScript 对象图视为一个堆(heap)。 Blink 中实现了 Oilpan,但以垃圾收集库的形式迁移到了 V8。目标是使所有 V8 嵌入程序和更多的 C++ 开发人员都可以轻松使用 C ++ 垃圾回收。
目前Oilpan的定位相当于一个C++对象回收的模块库,任何项目都可调用。在v8中是与Orinoco配合使用,虽然功能重合,但是Oilpan可以对C++进行GC。
在目前的文章中介绍的是Oilpan的GC标记-清除算法。在标记阶段实现了并发标记。对于清除阶段,使用了增量与并发清除技术。
源码分析
1 | // incremental-marking.cc 并发标记根索引的对象,将对象涂灰并压入处理栈 |
GC reason
1 | // heap.h 枚举了需要用到GC的情况,可以以此为入口点全局搜索字符串来找到所有用到GC的情况。头文件2600行我淦 |
之后动态调试追踪一下这个函数,我们使用如下代码触发Minor GC
1 | var a = []; |
函数原型如下
1 | bool Heap::CollectGarbage(AllocationSpace space, |
下断点进行调试
1 | b v8::internal::Heap::CollectGarbage(v8::internal::AllocationSpace, v8::internal::GarbageCollectionReason, v8::GCCallbackFlags) |
Scavenger垃圾回收
1 | // 首先建立一个全局的概念,v8官方博客已经描述了使用的相关技术,核心就是更好的利用了多线程,并行Scavenger将标记-复制-修改指针过程变为原子过程,V8使用多线程和负载平衡机制来扫描Root(增量回收)。 |
MARK_COMPACTOR垃圾回收
在上面的调试过程达到了case的步骤
1 | switch (collector) { |
这次我们要分析Major GC,所以自然进入 MarkCompact函数执行
编写如下代码触发该case
1 | new ArrayBuffer(0x80000000); |
此时触发了MajorGC
1 | pwndbg> print collector |
还是先看下整体的流程
1 | // 逻辑比较清晰, mark_compact_collector()->Prepare()进行增量标记环境的创建,MarkCompactPrologue函数清理各个位置的缓存。 |
就算了解了相关的算法知识以及有较为丰富的注释,但观察源代码理解这个庞大的GC过程仍然比较痛苦,尤其是和并发与并行沾上边,而且需要对某些位置进行mutex限制访问,目前对于源代码的分析就简单于此,笔者需要补充自己的实力与经验再去挑战一下v8的GC实现了。
参考链接
《垃圾回收的算法与实现》 // [日]中村成洋 相川光
https://www.cnblogs.com/qqmomery/category/719315.html // GC总结
https://www.jianshu.com/p/12544c0ad5c1 // 三色标记法详解
https://juejin.cn/post/6896363424398180359 // GC总结
https://juejin.cn/post/6844904161654341646 // v8相关总结
https://time.geekbang.org/column/intro/296?tab=catalog // 图解google v8